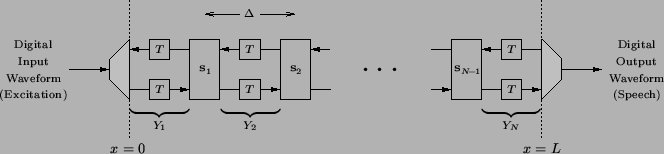
Now that we have discussed both the digital delay line representation of wave propagation within a single acoustic tube, as well as the scattering that occurs at any junction between adjacent tubes, we are now ready to present the full discrete-time model of the vocal tract. For an ![]() tube model of the vocal tract, then, we will have the digital signal flow graph shown in Figure 1.4. Here, the scattering junctions are indicated by rectangles, marked by
tube model of the vocal tract, then, we will have the digital signal flow graph shown in Figure 1.4. Here, the scattering junctions are indicated by rectangles, marked by
![]() (representing a matrix transformation of the form of (1.8) or (1.10), which is parametrized by
(representing a matrix transformation of the form of (1.8) or (1.10), which is parametrized by
![]() , which itself depends on the adjoining tube admittances
, which itself depends on the adjoining tube admittances ![]() and
and ![]() ).
).
The structure is driven at the left end, by an input waveform (typically an impulse train, for voiced speech or by white noise for unvoiced speech, or a combination of the two), and an output speech waveform is emitted at the right end. The grey boxes, representing boundary conditions at the glottis and lips, we leave unspecified--such terminations can be modeled in a variety of ways [145].
Leaving aside a discussion of these boundaries, we can see that a single cycle in the recursive structure shown in Figure 1.4 (one pass through the main loop of the computer program that it implies) will involve two distinct steps:

Several other features are worthy of comment. First, we have treated the vocal tract here as a static or time-invariant linear (LTI) system. As we mentioned before, however, the configuration of the vocal tract must necessarily change during any utterance--these variations are assumed to be slow with respect to the frequency content of the excitation. The slow variation in the acoustic tube profile will cause shifts in the system resonances (formants), and these shifts will be perceived, by the listener, as phoneme transitions. In our discussion of scattering and energy conservation in the Kelly-Lochbaum model, we have not taken the time variation of the tube cross-sectional areas (and thus the reflection coefficients) into account. It should be clear, though, that if we are using the power-normalized signal variables defined by (1.9), then scattering defined by (1.10) at any junction remains an orthogonal (and thus norm preserving) operation, even if the
![]() are functions of time
are functions of time![]() [166]. Second, it is also simple to extend the model to include the nasal pathways (necessary for the production of certain vocal sounds, and also modeled as acoustic tubes [30]), without compromising overall losslessness. Third, we note that the stability of this model can be maintained even if the reflection coefficients
[166]. Second, it is also simple to extend the model to include the nasal pathways (necessary for the production of certain vocal sounds, and also modeled as acoustic tubes [30]), without compromising overall losslessness. Third, we note that the stability of this model can be maintained even if the reflection coefficients
![]() are quantized [166]--this will necessarily occur in any finite word-length machine implementation. As long as the quantized coefficients remain bounded by 1, then we still have a perfectly lossless system. Signal quantization can also be performed so as to maintain overall stability, though the system will become more generally passive and not strictly lossless. Fourth, although the acoustic tube of varying cross-sectional area is often considered to be analogous to a lossless electrical transmission line of spatially-varying inductance and capacitance, it is better thought of as a special case of the latter. For the acoustic tube, the local admittance varies directly with the cross-sectional area, but the wave speed
are quantized [166]--this will necessarily occur in any finite word-length machine implementation. As long as the quantized coefficients remain bounded by 1, then we still have a perfectly lossless system. Signal quantization can also be performed so as to maintain overall stability, though the system will become more generally passive and not strictly lossless. Fourth, although the acoustic tube of varying cross-sectional area is often considered to be analogous to a lossless electrical transmission line of spatially-varying inductance and capacitance, it is better thought of as a special case of the latter. For the acoustic tube, the local admittance varies directly with the cross-sectional area, but the wave speed ![]() remains constant; this is important, because for a given tube length of
remains constant; this is important, because for a given tube length of ![]() , the time delay is dependent on the wave speed, from (1.4). For a transmission line, both the admittance and the wave speed may vary from point to point along its length. We cannot then approximate the full transmission line by concatenated uniform transmission line segments in the same way as for the acoustic tube without losing synchronization of the resulting discrete-time structure (i.e., delay durations in the segments are not all the same). We will show how to solve this problem in Chapter 4.
, the time delay is dependent on the wave speed, from (1.4). For a transmission line, both the admittance and the wave speed may vary from point to point along its length. We cannot then approximate the full transmission line by concatenated uniform transmission line segments in the same way as for the acoustic tube without losing synchronization of the resulting discrete-time structure (i.e., delay durations in the segments are not all the same). We will show how to solve this problem in Chapter 4.