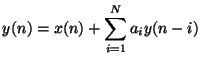Discrete-time structures such as that shown in Figure 1.4 are also used in digital filtering applications [134,139], in which case, the notion of a spatial location associated with a particular junction or delay element is often lost. For example, consider the digital filter structure shown in Figure 1.5(a).
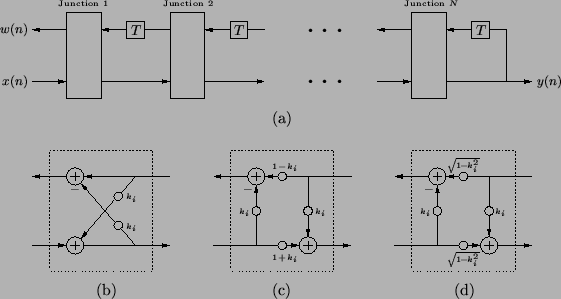 |
The structure of Figure 1.5(a) is quite similar to the Kelly-Lochbaum discrete-time acoustic tube model, but there are two minor differences. First, the Kelly-Lochbaum structure contains delay elements in both the leftward and rightward signal paths, reflecting the traveling-wave nature of the solution to the physical acoustic tube problem. In the lattice filter structure, however, the delays all occur in the upper (leftward) signal path. It is possible to transform the Kelly-Lochbaum structure into the lattice form by signal flow-graph manipulations involving pushing delays through the junctions, combining them, and then downsampling by a factor of two--this can be done provided the acoustic tube model is terminated by a zero or infinite impedance at the right end [166]. (We remark that this downsampling operation can also be applied to digital waveguide meshes in higher dimensions, in which case we will refer to it as grid decimation; we will examine grid decimation for a variety of mesh forms in Appendix A.) Second, the Kelly-Lochbaum and normalized junctions in our treatment of the acoustic tube model differ slightly from the signal flow graphs shown in Figure 1.5(c) and (d). This difference is due to our choice of pressure waves instead of velocity waves as our signal set. While these quantities are dual in the one-dimensional acoustic tube, this symmetry is lost when we move to acoustics problems in higher dimensions, and it is more natural to work with pressure variables![]() .
.
The same lattice structure is also arrived at in the analysis context when linear predictive coding (LPC) techniques are applied to a speech waveform [124]. The assumption underlying LPC is that speech can be treated as a source signal (such as a glottal waveform), filtered by the vocal tract, and the goal is to design an all-pole filter of the form of (1.11) which models the system resonances (or formant structure). Though this filter is obtained through purely autoregressive (i.e., non-physical) analysis of a given measured speech signal, the reflection coefficients ![]() (also known as partial correlation or PARCOR coefficients) are calculated as a byproduct of the main calculation of the direct form filter coefficients
(also known as partial correlation or PARCOR coefficients) are calculated as a byproduct of the main calculation of the direct form filter coefficients ![]() . The
. The ![]() are identical to the
are identical to the
![]() in the acoustic tube model, except for a sign inversion. This is not to say that the filter arrived at through LPC immediately implies a particular vocal-tract shape; it is best thought of as the solution to a filter-design or system identification problem, devoid of any physical interpretation [145]. We note, though, that transmission-line models such as the concatenated acoustic tube model have long been used for such system identification purposes in the inverse scattering context, in which case they are sometimes referred to as ``layer-peeling'' or ``layer-adjoining'' methods [22,23,213]. Provided certain assumptions are made about the glottal waveform and the effects of radiation on the measured speech waveform, it is possible to make some inferences about the vocal tract shape [30].
in the acoustic tube model, except for a sign inversion. This is not to say that the filter arrived at through LPC immediately implies a particular vocal-tract shape; it is best thought of as the solution to a filter-design or system identification problem, devoid of any physical interpretation [145]. We note, though, that transmission-line models such as the concatenated acoustic tube model have long been used for such system identification purposes in the inverse scattering context, in which case they are sometimes referred to as ``layer-peeling'' or ``layer-adjoining'' methods [22,23,213]. Provided certain assumptions are made about the glottal waveform and the effects of radiation on the measured speech waveform, it is possible to make some inferences about the vocal tract shape [30].