Unsupervised Feature Learning for Music and Audio
For my PhD thesis, I explored unsupervised feature learning for musical data and applied them to music classification, annotation and transcription.
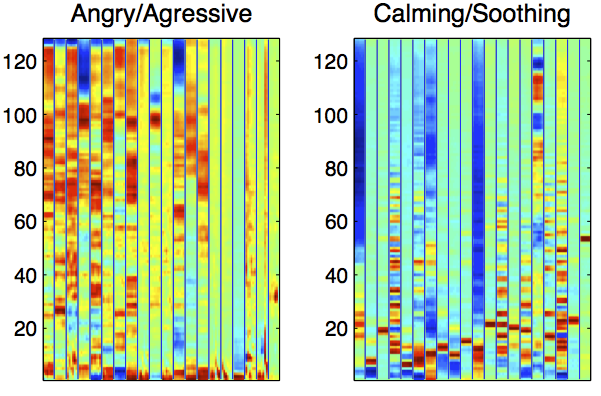
Feature Learning for Music Classification and Annotation
This presents an effective data processing
pipeline to find feature representations from musical signals
using unsupervised learning algorithms. This learning-based feature representations
were utilized in music genre classification, annotation (a.k.a tagging) and text-based retrieval tasks.
[webpage]
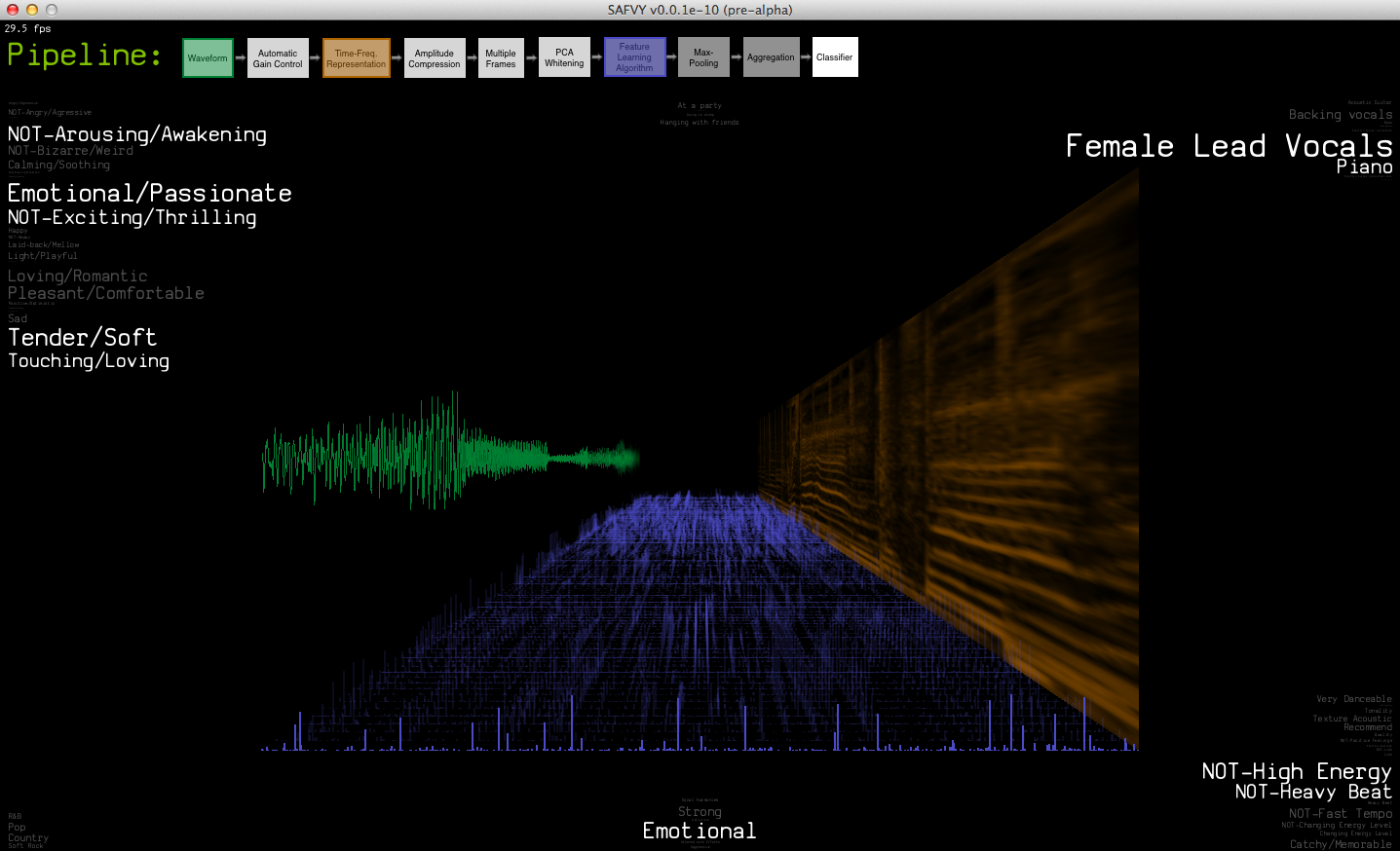
SAFVY! - Real-Time Music Tagging Visualizer
A real-time music tagging demo that shows data/feature representations as well as estimated tags
that describes music in semantic levels (e.g. genre, emotion, instrument, voice quality and other semantic words)
[webpage]
Polyphonic Piano Transcription Using Learned Audio Features
We applied the feature learning idea to polyphonic piano transcription. Based on a classification approach
(i.e. a binary classifier determines the presence of a single note), we pre-trained a neural
networks in an unsupervised way and then fine-tuned the networks using the errors which are
simultaneously propagated from multiple note classifiers.
[paper] [poster]
Sound Representation and Recognition
I spent some time working on new sound representation and recognition methods using probabilistic latent component analysis (PLCA), which is a probabilistic version of non-negative matrix factorization (NMF).
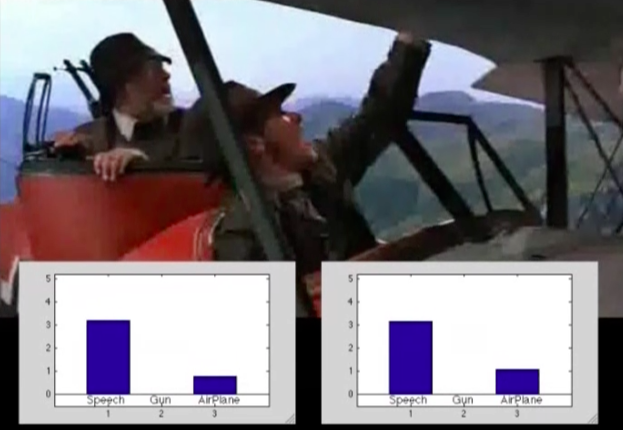
Sound Recognition in Mixture
This presents a method for recognizing sound sources in a mixture.
The method is based on a source separation idea using the PLCA but estimates relative proportions of the mixture
without separating the sources.
[webpage]
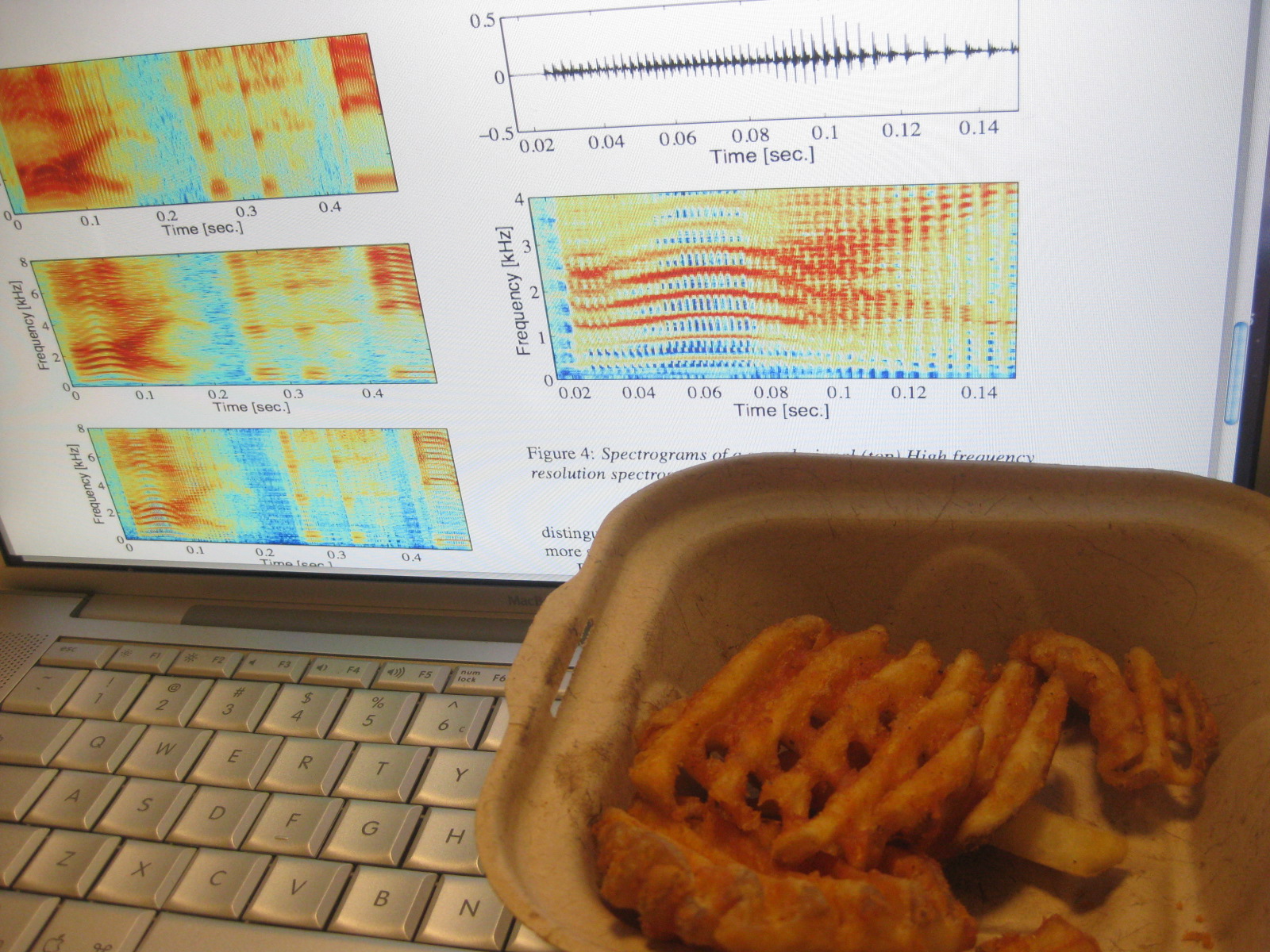
Super-Resolution Spectrogram
The short-time Fourier transform (STFT) based spectrogram intrinsically has a trade-off
in time and frequency resolution when it is displayed as a 2-D time-frequency representation.
We propose an idea to achieve high resolutions in both time and frequency using PLCA.
[webpage]
Sound Synthesis
Sound synthesis is my longtime favorite. I love to learn and explore various sound synthesis techniques and sound design using them. This introduces my research work that I spent quite a while.

Virtual Analog Oscillators
With Vesa Välimäki and
Jussi Pekonen at Aalto University,
I came up with several different algorithms to efficiently generate bandlimited (anti-aliasing) oscillators,
which are used in virtual analog synthesizers. This briefly introduces a class of algorithms among them.
[webpage]
Spatial Audio
ThreeDee: Binaural Sound Processor
This shows a 3-D sound processing demo working in real-time.
It uses head-related transfer functions (HRTFs) to synthesize binaural sounds
from monaural sources. We measured the HRTFs from human subjects and
efficiently modeled them using their minimum-phase characteristic.
[webpage]