Learning Feature Representations for Music Classification
This page summarizes the main part of my PhD research and also shows supplementary audio/video examples.
Introduction
Finding salient features that characterize different types of music is one of the key elements in content-based music classification. Conventionally, these features have been engineered based on acoustic or musical knowledge, such as in mel-frequency cepstral coefficients (MFCCs) or chroma. As an alternative approach, there is increasing interest in learning features automatically from data without relying on domain knowledge or manual refinement. My thesis investigates the learning-based feature representation with applications to content-based music classification.
Feature Representations Learned From Music Data
Musical signals are highly variable and complex data. However, they are structured well in terms of timbre, pitch, harmony and rhythm. The structured patterns eventually determine high-level semantics of music, such as genre and mood. We find the dependency patterns in data space using unsupervised learning algorithms and use them to represent features.
Before applying musical data to learning algorithms, we performed preprocessing which normalizes the data and transforms it into mel-frequency spectrogram. After learning local features using algorithms, we summarize them over a song. The following shows our proposed data processing pipeline, which eventually returns a song-level feature vector.
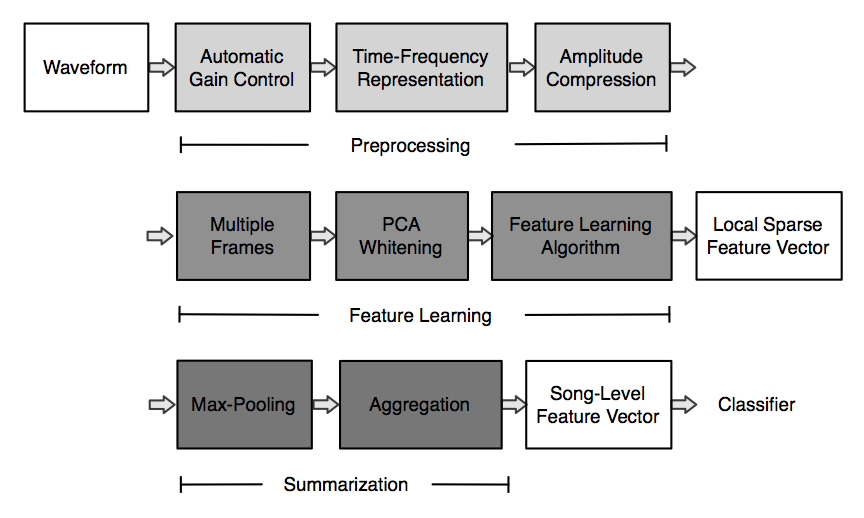
We examined several different unsupervised feature learning algorithms including K-means, sparse coding, Restricted Boltzmann Machine (RBM) and auto-encoder. The following examples show feature bases learned from the algorithms. The animation shows how the feature bases converge in sparse coding. We used multiple frames of mel-frequency spectrogram as training data.
Semantic Interpretation
These learned features can be described by their spectral patterns (e.g. harmonic/non-harmonic, transient/stationary or low/high-frequency energy). Furthermore, we attempted to interpret them in terms of high-level semantics using rich tag labels (genre, emotion, instrument, usage, voice quality... ) in the CAL500 dataset. This was conducted by finding most actively "triggered" feature bases for a subset that contains a specific tag. The following shows top-20 most active feature bases for different tags. Note that these are selected from the same dictionary learned above.
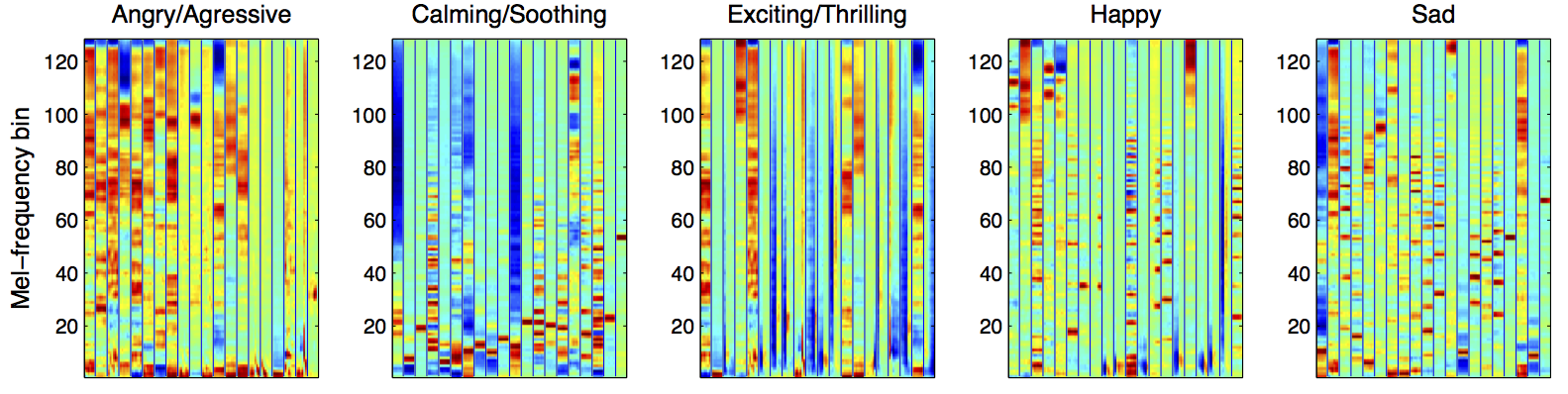
Emotion

Genre

Instrument
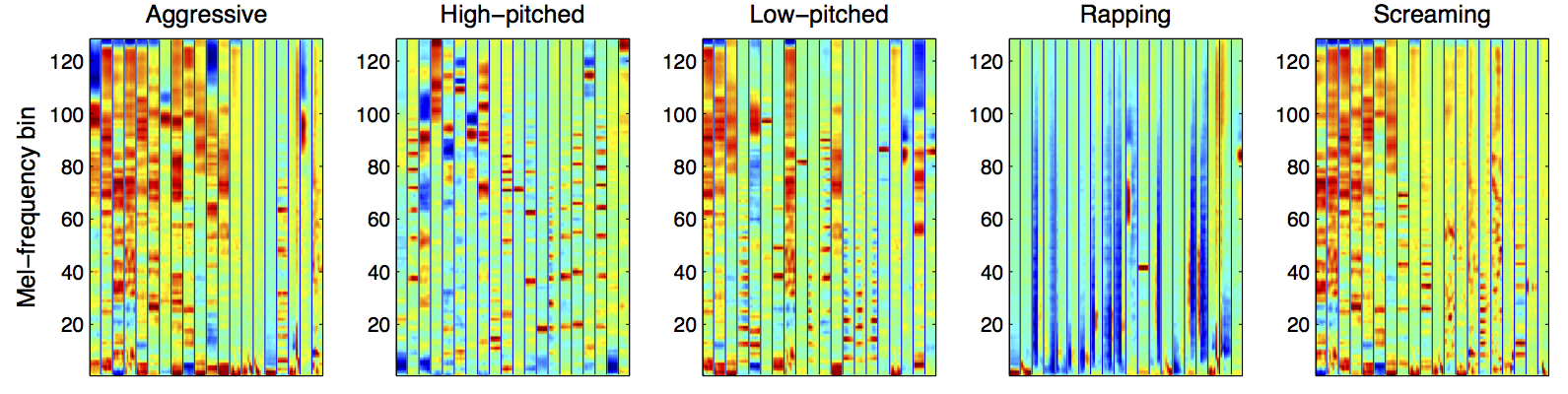
Vocal
You can see that the acoustic feature patterns are quite intuitively related to high-level semantics. For example, songs with ''Angry/Aggressive'', ''Rock'', ''Electric Guitar (Distortion)'' and ''Screaming'' tags have strong high frequency energy. Songs with ''Electronica'', ''DrumMachine'', ''Hiphop/Rap'' and ''Rapping'' tags have very low-frequency energy patterns which seem to be triggered by bass drum. Likewise, other feature patterns can be interpreted in a similar manner.
Reconstructed Audio from Feature Representations
These learned features can be examined in terms of audio quality reconstructed from features because it directly indicates that what kinds of audio contents are contained in the features. For comparison, we first show audio examples reconstructed from MFCC and Chroma.
| Original Input | |
| MFCC | |
| Chroma |
These hand-crafted features are designed to extract a very specific aspect of sounds, i.e., spectral envelop (MFCC) or 12-pitch class distribution (Chroma). These are not sufficient to capture all possible musical variations that determines various musical semantics. On the other hand, the proposed feature representations reproduce the original input sounds similarly. Here we list reconstructed audio examples from each stage of the data processing pipeline above.
| Original Input | |
| Time-Freq. AGC | |
| Mel-spectrogram | |
| PCA whitening | |
| RBM |
Note that since good reconstruction is not the main objective (we also have a sparsity term which prompts features to be more discriminative), the audio quality is not so great. However, you can hear the original sound without severe artifacts, compared to MFCC or Chroma.
Applications to music tag classification
We applied these learned features for music genre classification, music annotation and retrieval and achieved superior results to many of previous approaches. The details of analysis and evaluations can be found at the papers below.
Publications
- Juhan Nam, "Learning Feature Representations for Music Classification," Ph.D. thesis, Stanford University, 2012
- Juhan Nam, Jorge Herrera, Malcolm Slaney and Julius O. Smith, " Learning Sparse Feature Representations for Music Annotation and Retrieval," In Proceedings of the 13th International Conference for Music Information Retrieval (ISMIR) Conference, 2012