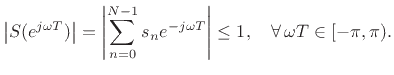In typical string models for virtual musical instruments, the ``nut
end'' of the string is rigidly clamped while the ``bridge end'' is
terminated in a passive reflectance ![]() . The condition
for passivity of the reflectance is simply that its gain be bounded
by 1 at all frequencies [450]:
. The condition
for passivity of the reflectance is simply that its gain be bounded
by 1 at all frequencies [450]:
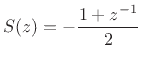
To impose this lowpass-filtered reflectance on the right in the chosen subgrid, we may form

which results in the FDTD transition matrix
![\begin{eqnarray*}
\mbox{$\stackrel{{\scriptscriptstyle \vdash\!\!\dashv}}{\mathbf{A}}$}_K&\isdef &
\left[\!
\begin{array}{ccccccccccc}
0 & -1 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & -1 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & -1 & 1 & -1 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & -1 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & -1 & 1 & -1 & 1 & 0 \\
0 & 0 & 0 & 0 & 1 & -1 & 1 & 0 \\
0 & 0 & 0 & 0 & 1/2 & -1/2 & 0 & 0 \\
0 & 0 & 0 & 0 & -1/2 & 1/2 & -1 & -1
\end{array}\!\right].
\end{eqnarray*}](img4792.png)
This gives the desired filter in a half-rate, staggered grid case. In the full-rate case, the termination filter is really
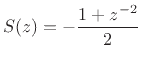
which is still passive, since it obeys Eq.(E.42), but it does not have the desired amplitude response: Instead, it has a notch (gain of 0) at one-fourth the sampling rate, and the gain comes back up to 1 at half the sampling rate. In a full-rate scheme, the two-point-average filter must straddle both subgrids.
Another often-used string termination filter in digital waveguide models is specified by [450]
![\begin{eqnarray*}
s(n) &=& -g\left[\frac{h}{4}, \frac{1}{2}, \frac{h}{4}\right]\\
\longleftrightarrow\quad S(e^{j\omega T})&=&
-e^{-j\omega T}g\frac{1 + h \cos(\omega T)}{2},
\end{eqnarray*}](img4794.png)
where ![]() is an overall gain factor that affects the decay
rate of all frequencies equally, while
is an overall gain factor that affects the decay
rate of all frequencies equally, while ![]() controls the
relative decay rate of low-frequencies and high frequencies. An
advantage of this termination filter is that the delay is
always one sample, for all frequencies and for all parameter settings;
as a result, the tuning of the string is invariant with respect to
termination filtering. In this case, the perturbation is
controls the
relative decay rate of low-frequencies and high frequencies. An
advantage of this termination filter is that the delay is
always one sample, for all frequencies and for all parameter settings;
as a result, the tuning of the string is invariant with respect to
termination filtering. In this case, the perturbation is
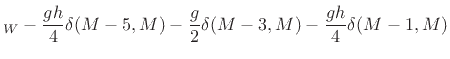
and, using Eq.(E.41), the order
![\begin{eqnarray*}
\mbox{$\stackrel{{\scriptscriptstyle \vdash\!\!\dashv}}{\mathbf{A}}$}_K&\isdef &
\left[\!
\begin{array}{ccccccccccc}
0 & -1 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & -1 & 1 & 0 & 0 & 0 & 0 & 0 \\
1 & -1 & 1 & -1 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & -1 & 1 & 0 & 0 & 0 \\
0 & 0 & 1 & -1 & 1 & -1 & 1 & 0 \\
0 & 0 & 0 & 0 & 1 & -1 & 1 & 0 \\
0 & 0 & g_1 & -g_1 & 1+g_2 & -1-g_2 & 1+g_3 & -1-g_3 \\
0 & 0 & g_1 & -g_1 & \quad g_2 & \quad -g_2 & \quad g_3 & \quad -g_3
\end{array}\!\right]
\end{eqnarray*}](img4798.png)
where
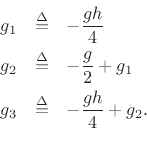
The filtered termination examples of this section generalize
immediately to arbitrary finite-impulse response (FIR) termination
filters ![]() . Denote the impulse response of the termination filter
by
. Denote the impulse response of the termination filter
by
where the length