 |
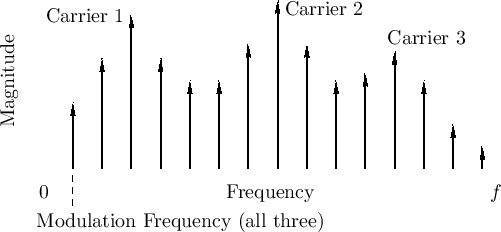
FM voice synthesis [39] can be viewed as compressed modeling of spectral formants. Figure G.8 shows the general idea. This kind of spectral approximation was used by John Chowning and others at CCRMA in the 1980s and beyond to develop convincing voices using FM. Another nice example was the FM piano developed by John Chowning and David Bristow [41].
A basic
FM operator,
consisting of two sinusoidal oscillators
(a ``modulator'' and a ``carrier'' oscillator, as written
in Eq.(G.2)), can synthesize a useful approximation to
a formant group in a harmonic line spectrum. In this
technique, the carrier frequency is set near the formant center
frequency, rounded to the nearest harmonic frequency, and the
modulating frequency is set to the desired pitch (e.g., of a sung
voice [39]). The modulation index is set to give the
desired bandwidth for the formant group. For the singing
voice, three or more formant groups yields a
sung vowel sound. Thus, a sung vowel can be synthesized using
only six sinusoidal oscillators using FM. In straight additive
synthesis, a bound on the number of oscillators needed is given by the
upper band-limit divided by the fundamental frequency, which could be,
for a strongly projecting deep male voice, on the order of ![]() kHz
divided by 100 Hz, or 200 oscillators.
kHz
divided by 100 Hz, or 200 oscillators.
Today, FM synthesis is still a powerful spectral modeling technique in which ``formant harmonic groups'' are approximated by the spectrum of an elementary FM oscillator pair. This remains a valuable tool in environments where memory access is limited, such as in VLSI chips used in hand-held devices, as it requires less memory than wavetable synthesis (§G.8.4).
In the context of audio coding, FM synthesis can be considered a ``lossy compression method'' for additive synthesis.