Concavity is valuable in connection with the Gradient Method of
minimizing
![]() with respect to
with respect to
![]() .
.
Definition. The gradient of the error measure
![]() is defined as the
is defined as the
![]() column vector
column vector
![$\displaystyle {J^\prime}({\hat \theta})\mathrel{\stackrel{\mathrm{\Delta}}{=}}\...
...ial}{\partial \theta}{J(\theta)}{a_{n_a}}\left({\hat a}_{n_a}\right)\right]^T.
$](img129.png)
Definition. The Gradient Method (Cauchy) is defined as follows.
Given
![]() , compute
, compute
Some general results regarding the Gradient Method are given below.
Theorem. If
![]() is a local minimizer of
is a local minimizer of
![]() , and
, and
![]() exists, then
exists, then
![]() .
.
Theorem. The gradient method is a descent method, i.e.,
![]() .
.
Definition.
![]() ,
,
![]() , is
said to be in the class
, is
said to be in the class
![]() if all
if all ![]() th order partial
derivatives of
th order partial
derivatives of
![]() with respect to the components of
with respect to the components of
![]() are
continuous on
are
continuous on
![]() .
.
Definition. The Hessian
![]() of
of ![]() at
at
![]() is defined as the matrix
of second-order partial derivatives,
is defined as the matrix
of second-order partial derivatives,
![$\displaystyle {J^{\prime\prime}}({\hat \theta}) [i,j] \mathrel{\stackrel{\mathr...
...c{\partial^2 J(\theta)}{\partial \theta[i]\partial \theta[j]} ({\hat \theta}),
$](img147.png)
The Hessian of every element of
![]() is a symmetric
matrix [7]. This is because continuous second-order
partials satisfy
is a symmetric
matrix [7]. This is because continuous second-order
partials satisfy
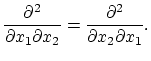
Theorem. If
![]() , then any cluster point
, then any cluster point
![]() of the gradient sequence
of the gradient sequence
![]() is necessarily a
stationary point, i.e.,
is necessarily a
stationary point, i.e.,
![]() .
.
Theorem. Let
![]() denote the concave hull of
denote the concave hull of
![]() . If
. If
![]() , and there exist
positive constants
, and there exist
positive constants ![]() and
and ![]() such that
such that
By the norm equivalence theorem [4], Eq. (4) is satisfied whenever
![]() is a norm on
is a norm on
![]() for each
for each
![]() . Since
. Since
![]() belongs to
belongs to
![]() , it is a symmetric matrix. It is also
bounded since it is continuous over a compact set. Thus a sufficient
requirement is that
, it is a symmetric matrix. It is also
bounded since it is continuous over a compact set. Thus a sufficient
requirement is that
![]() be positive definite on
be positive definite on
![]() . Positive
definiteness of
. Positive
definiteness of
![]() can be viewed as ``positive curvature'' of
can be viewed as ``positive curvature'' of ![]() at
each point of
at
each point of
![]() which corresponds to strict concavity of
which corresponds to strict concavity of ![]() on
on
![]() .
.