In plain terms, a time-invariant
filter (or shift-invariant
filter) is one which performs the
same operation at all times. It is awkward to express this
mathematically by restrictions on Eq.(4.2) because of the use of
![]() as the symbol for the filter input. What we want to say is
that if the input signal is delayed (shifted) by, say,
as the symbol for the filter input. What we want to say is
that if the input signal is delayed (shifted) by, say, ![]() samples,
then the output waveform is simply delayed by
samples,
then the output waveform is simply delayed by ![]() samples and
unchanged otherwise. Thus
samples and
unchanged otherwise. Thus ![]() , the output waveform from a
time-invariant filter, merely shifts forward or backward in
time as the input waveform
, the output waveform from a
time-invariant filter, merely shifts forward or backward in
time as the input waveform ![]() is shifted forward or backward
in time.
is shifted forward or backward
in time.
Definition. A digital filter
![]() is said to be
time-invariant
if, for every input signal
is said to be
time-invariant
if, for every input signal ![]() , we have
, we have
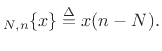
On the signal level, we can write
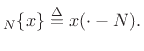
Thus, SHIFT