Stereo signals need some special considerations to exploit all redundancies:
Experiments has been performed on the assumption that, in every frequency band, the signal is only a panned monophonic signal, i.e the same signal is in both channels except for a scaling factor. The left and right channel is seen as two vectors, orthogonal to each other (see figure 7). The signal data in a band is used to least-square-fit a vector between the two vectors, representing the most probable direction (the optimal direction would be found with an SVD, though). This vector, and an orthogonal counterpart, is chosen to be the new basis for the signal, and the left and right signals are transformed to the new basis. Even without counting the bits for the basis information, this did not improve the results from just the mean-difference approach.
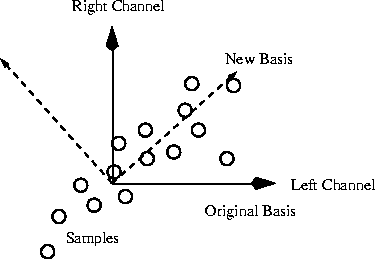
Figure: The left-right stereo model, discussed in section 4.3.