The coder has been tested and developed mainly with about 10 second sampels from music CD's, most of which are in the table below. After finishing the development, the MPEG-2 testfile music.wav, containing many hard instruments, was tested. Some of the instruments were treated well, and some, like for example the castanets sounded rather bad. The castanetes of course require some kind of pre-echo detection to sound good. Some examples take from that music.wav are shown below.
All of the following samples can be found in wav format on the web, at http://www-ccrma.stanford.edu/~ bosse/. Note that no rate controlling module is developed, and thus bitrates vary a lot with the type of signal. From the values below, one can deduce that a fair perceptual lossless coding can be achieved at about 128 kbit/second for stereo data and 75 kbit/second for mono.
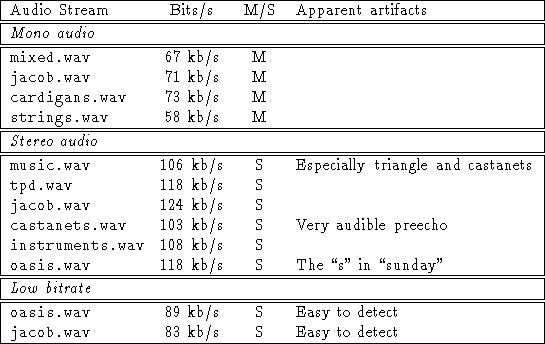
M/S means mono/stereo. The low bitrate signals are coded with a
masking threshold multiplied by a factor ![]() and
and ![]() respectively.
respectively.
The encoder described in this report is apparently rather undeveloped. To improve the coder, I would like to add some kind of transient coding, for example using wavelets. Transform-wavelet hybrid coders (see e.g [11]) has become more popular and show good results. Also, an adaptive prediction in either the time- or transform domain would decrease bitrate in stationary signals (although some of this is exploited by the KLT).
This project has not not resulted in a coder with many new features, but in some experience and knowledege for me in the field of high fidelity perceptual audio coders.