
Stereo Widening Plugin
Stereo widening is a toolkit in every mastering engineer's arsenal, that can greatly enhance the spaciousness of a stereo mix. It can also be used on mono tracks to increase source width. I have designed an open-source stereo widening plugin made with JUCE (C++) that uses decorrelation and mixing. Perceptually informed allpass filters and optimised velvet noise filters are used as decorrelators with independent control of the perceived width in lower and higher frequency regions. A transient handling block prevents smearing of percussive signals caused by the decorrelation block. Sound examples of the plugin (compared with an interaural delay based widener) are available here.
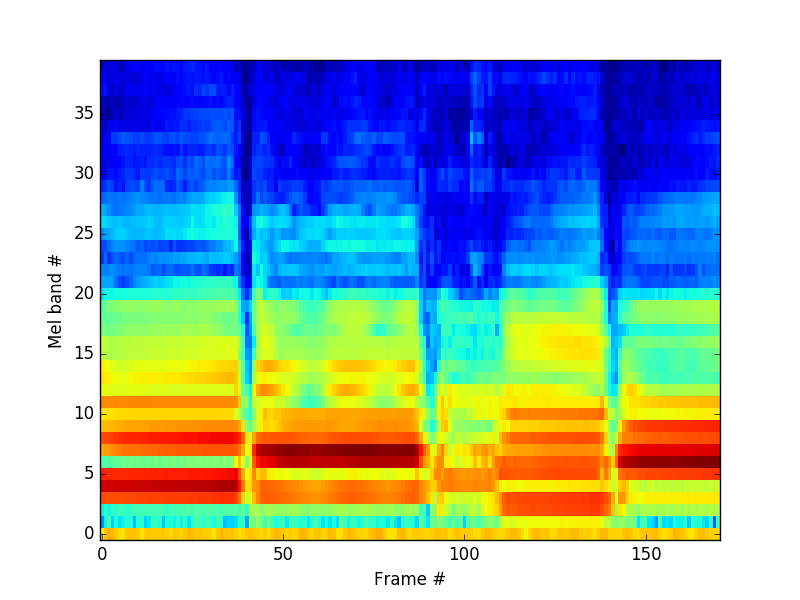
Musical Instrument Identification with Supervised Learning - CS 229 Final Project
The classification of musical instruments using supervised learning is studied. A combined feature set including psychoacoustically relevant spectral features consisting of MFCCs and Warped LPCs, is used. A fairly small dataset consisting of 496 sound examples from 4 instruments - violin, clarinet, saxophone and bassoon is used (Bach10 dataset). Perfect classification accuracy is achieved on the test set with multi-class logistic regression and SVM with RBF kernel.

Psychoacoustic Dissonance Measurement in Reverberant Spaces - Music 251 Final Project
A pilot study is conducted to investigate how the perception of musical dissonance is affected by reverberation. 22 subjects are asked to rate chord snippets with varying dissonance and reverberation decay times. The chord sequences are MIDI, and reverb is added using the

A Darker Phonetic Audio Coder - Music 422 Final Project
Implementation of an end-to-end psychoacoustic audio coder. On top of the baseline coder that included frequency transformation (MDCT), generating psychoacoustic masking curves, quantization and bit allocation strategies, additional features such as M/S stereo coding, Huffman coding, Block Switching and Bit reservoir were implemented. Listening test results and compression ratios at 128 kbps showed promising results.

Guitarist Classification from Guitar Solo Tabs - Music 364 Final Project
Artist Identification by analyzing musical score is a unique problem in MIR. In this project, we tackle the novel problem of automatically classifying guitarists by analyzing guitar solo tabs. We have created a hand-curated dataset of 80 guitar solos downloaded in MusicXML format played by Eric Clapton, David Gilmour, Mark Knopfler and Jimi Hendrix. The solos have been cleaned and converted to tuples containing note duration, transposed fret and string. We have tried to visualize the stylistic difference between artists by computing pitch class and beat histograms and self-similarity matrices. As an initial classification paradigm, we have used zero and first-order Markov chains, the latter giving significantly above chance classification accuracy. Future work would be to employ some modern sequence based classification techniques for better results.

No Pain No Sustain - EE 264/Music 220C Final Project
An audio effect to extend the sustain of a musical note in real-time is implemented on a fixed point, standalone processor -- DSP shield running TI C5535. Onset detection is performed with a leaky integrator to look for new musical notes, and once they decay to steady state, the audio is looped indefinitely until a new onset comes along. To properly loop the audio, pitch detection is performed by looking for local minima in the Average Magnitude Difference Function (AMDF) to extract a period and the new output buffer is written in a phase aligned manner.

Effectrons - Music 256A/CS 476 Final Project
Effectrons is a guitar effects chain built in C++ with OpenFrameworks. The audio input is the nucleus of the cell, and the effects are electrons that rotate around in different orbital radii. Shoot lasers to hit the effects and change their radius to change effect parameters and generate new sounds. Rock it out with a guitar, or a GameTrak if you have one!

Chuck-o-der - Music 220A Final Project
Chuck-o-der is a vocoder built in ChucK that takes in input from the microphone and a MIDI synth, and modifies the magnitude spectrum of the MIDI synth according to the magnitude spectrum of the microphone input. This essentially is cross-synthesis with microphone input as the modulator and MIDI synth input as the carrier. Change the texture and pitch of your voice with the MIDI synth, and produce cool vocal sounds.

Chord Recognition
A fundamental MIR task that involves harmonic analysis of Western Music is chord recognition. The first step is to compute the Pitch Class Profile which tells us the constituent notes of a chord. To map individual musical notes to the frequency domain, the Constant Q Transform is used. In solo-instrument music, a simple Binary Template Matching is fairly successful in recognising chords. However, in complex multi-instrumental music advanced methods, such as, Hidden Markov Models are used.

Speaker Recognition
Speaker Recognition is the process of identifying a unique speaker by analyzing their speech. The main objective was to implement well-known speaker recognition algorithms in Python, which is becoming the language of choice for scientific computing. Two features - MFCCs and LPCs are extracted from each speaker and Vector Quantization (or K-means clustering) with LBG (Linde, Buzo, Gray) algorithm is used to train the data set and form speaker-specific codebooks.

Digital Audio Effects
Audio effects are used extensively in music performance and production. With the aid of digital computers and simple audio filters, it is possible to simulate them easily on a microcontroller/ personal computer. This was a presentation done as part of a Seminar in my pre-final year curriculum, where I merely scratched the mad world of guitar effects. The signal processing behind distortion, overdrive, wah-wah, tremolo and flanger was explored and implemented in MATLAB. I wish to expand this and build a real-time Arduino based guitar effects processor.