Q3osc: overview

q3osc is a heavily modified version of the ioquake3 gaming engine featuring an integrated oscpack implementation of Open Sound Control for bi-directional communication between a game server and a multi-channel ChucK audio server. By leveraging ioquake3’s robust physics engine and multiplayer network code with oscpack’s fully-featured OSC specification, game clients and previously unintelligent in-game weapon projectiles can be repurposed as behavior-driven independent OSC-emitting virtual sound-sources spatialized within a multi-channel audio environment for real-time networked performance.
Within the virtual environment, performers can fire different colored projectiles at any surface in the rendered 3D world to produce various musical sounds. As each projectile contacts the environment, the bounce location is then used to spatialize sound across the multi-speaker sound field in the real-world listening environment. Currently in use with the Stanford Laptop Orchestra or SLOrk, q3osc is designed to be scaled to work with a distributed environment of multiple computers and multiple hemspherical speaker arrays.
q3osc allows composers to program interactive performance environments using a combination of traditional gaming level-development tools and interactive audio processing softwares like ChucK, Supercollider, Pure Data or Max/MSP.
The composition nous sommes tous Fernando... was designed to be run using five slork hemispherical speakers arranged in a + shape with one speaker in the center and 1 speaker on each of the ends of the +. Each user sits at a slork station next to a hemispherical speaker. The center speaker is left un-manned and is connected to a subwoofer. Each physical speaker location has a unique number from 0-4 with 0 being the center speaker, being respectively - on a clock face - 1 being 12 o'clock, 2 being 3 o'clock, 3 being 6 o'clock, and 4 being 9 o'clock. These id's are used to identify each user's station to the software for correlation between virtual speaker placements and physical speaker placements (see diagram => ). All performers should be facing inwards towards the center speaker so that they can make eye and gestural contact with one another.
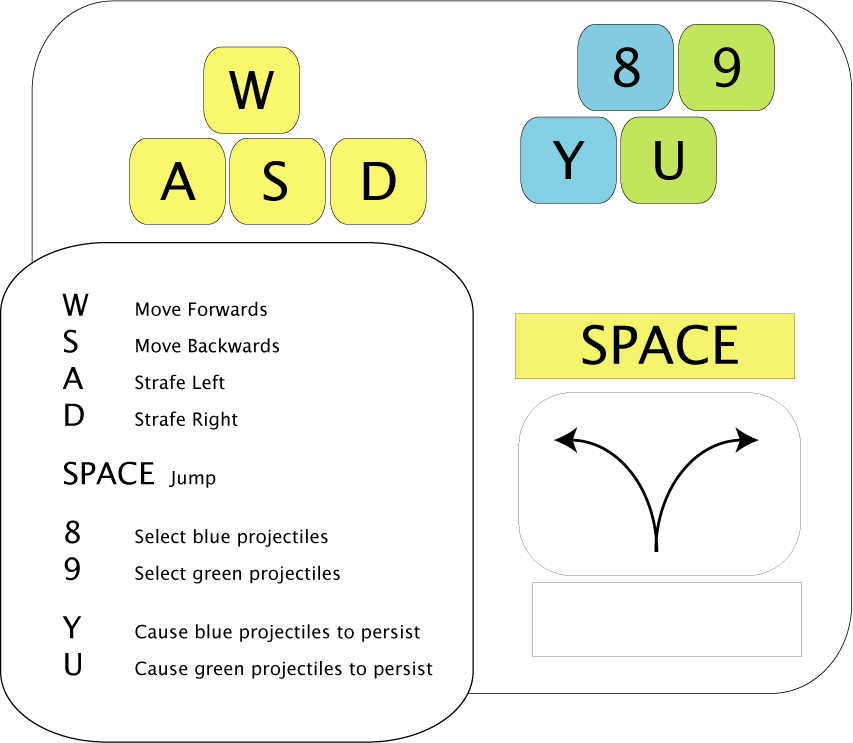
Controls