


Next: Singing
Up: Lectures
Previous: Speech Production
Speech recognition is a truly amazing human capacity, especially when you consider that normal conversation requires the recognition of 10 to 15 phonemes per second. It should be of little surprise then that attempts to make machine (computer) recognition systems have proven difficult. Despite these problems, a variety of systems are becoming available that achieve some success, usually by addressing one or two particular aspects of speech recognition.
A variety of speech synthesis systems, on the other hand, have been available for some time now. Though limited in capabilities and generally lacking the ``natural'' quality of human speech, these systems are now a common component in our lives.
- The first two or three formants are generally sufficient to identify vowel sounds.
- Under some conditions, however, vowels can be recognized from only the higher formants (when the lowest two are missing).
- The formant structure of young children is considerably different from that of adults, but we still recognize vowels spoken by children as being the same as those spoken by an adult.
- Vowel sounds are also recognized when the formant structure alone (not the fundamental pitch) is transposed (such as in helium speech).
- Sudden high frequency noise bursts followed by a vowel sound are generally heard as
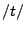 . Bursts at lower frequencies may be heard as
. Bursts at lower frequencies may be heard as  or
or 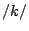 , depending on the vowel sound that follows.
, depending on the vowel sound that follows.
- Frequency transitions in the second format of the plosive noise burst provide recognition cues. Transitions which appear to originate from about 1800 Hz, 700 Hz, and 300 Hz produce the perception of the plosives , , and , respectively.
- The voiced plosives
 , and
, and 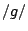 have upward first formant transitions, as well as upward or downward second formant transitions.
have upward first formant transitions, as well as upward or downward second formant transitions.
- The fricative ``sh'' has energy concentrated in the 2000 - 3000 Hz range.
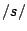 has energy concentrated above 4000 Hz.
has energy concentrated above 4000 Hz.
- Normal conversation is completely intelligible when listening only to components above 1800 Hz, or when listening only to components below 1800 Hz (bandpass filtered speech).
- Passbands of about 1000 Hz width also are sufficient for intelligible speech. Most narrowband (1/3-octave) filtered speech, however, is much more difficult to discern.
- Even after severe peak clipping, intelligibility remains high.
- Noise masking can reduce intelligibility of individual words by about 50% when the average intensities of the speech and noise are about equal. However, linguistic and semantic cues still allow intelligibility of sentences.
- Most, if not all, modern speech synthesizers use libraries of speech sounds, which are then concatenated together to form words. This requires the storage of vast databases of various sounds and their transitions.
- A synthesizer based on a physical model of the vocal tract will some day provide the most flexible speech synthesis system.


