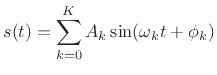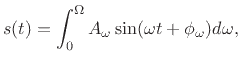This section reviews elementary spectral models for sound synthesis. Spectral models are well matched to audio perception because the ear is a kind of spectrum analyzer [293].
For periodic sounds, the component sinusoids are all
harmonics of a fundamental at frequency ![]() :
:
Aperiodic sounds can similarly be expressed as a continuous sum of sinusoids at potentially all frequencies in the range of human hearing:11.6
Sinusoidal models are most appropriate for ``tonal'' sounds such as
spoken or sung vowels, or the sounds of musical instruments in the
string, wind, brass, and ``tonal percussion'' families. Ideally, one
sinusoid suffices to represent each harmonic or overtone.11.7 To represent the ``attack'' and ``decay''
of natural tones, sinusoidal components are multiplied by an
amplitude envelope that varies over time. That is, the
amplitude ![]() in (10.15) is a slowly varying function of time;
similarly, to allow pitch variations such as vibrato, the phase
in (10.15) is a slowly varying function of time;
similarly, to allow pitch variations such as vibrato, the phase
![]() may be modulated in various ways.11.8 Sums of
amplitude- and/or frequency-enveloped sinusoids are generally called
additive synthesis (discussed further in §10.4.1
below).
may be modulated in various ways.11.8 Sums of
amplitude- and/or frequency-enveloped sinusoids are generally called
additive synthesis (discussed further in §10.4.1
below).
Sinusoidal models are ``unreasonably effective'' for tonal audio. Perhaps the main reason is that the ear focuses most acutely on peaks in the spectrum of a sound [179,306]. For example, when there is a strong spectral peak at a particular frequency, it tends to mask lower level sound energy at nearby frequencies. As a result, the ear-brain system is, to a first approximation, a ``spectral peak analyzer''. In modern audio coders [16,200] exploiting masking results in an order-of-magnitude data compression, on average, with no loss of quality, according to listening tests [25]. Thus, we may say more specifically that, to first order, the ear-brain system acts like a ``top ten percent spectral peak analyzer''.
For noise-like sounds, such as wind, scraping sounds, unvoiced speech, or breath-noise in a flute, sinusoidal models are relatively expensive, requiring many sinusoids across the audio band to model noise. It is therefore helpful to combine a sinusoidal model with some kind of noise model, such as pseudo-random numbers passed through a filter [249]. The ``Sines + Noise'' (S+N) model was developed to use filtered noise as a replacement for many sinusoids when modeling noise (to be discussed in §10.4.3 below).
Another situation in which sinusoidal models are inefficient is at sudden time-domain transients in a sound, such as percussive note onsets, ``glitchy'' sounds, or ``attacks'' of instrument tones more generally. From Fourier theory, we know that transients, too, can be modeled exactly, but only with large numbers of sinusoids at exactly the right phases and amplitudes. To obtain a more compact signal model, it is better to introduce an explicit transient model which works together with sinusoids and filtered noise to represent the sound more parsimoniously. Sines + Noise + Transients (S+N+T) models were developed to separately handle transients (§10.4.4).
A advantage of the explicit transient model in S+N+T models is that transients can be preserved during time-compression or expansion. That is, when a sound is stretched (without altering its pitch), it is usually desirable to preserve the transients (i.e., to keep their local time scales unchanged) and simply translate them to new times. This topic, known as Time-Scale Modification (TSM) will be considered further in §10.5 below.
In addition to S+N+T components, it is useful to superimpose spectral weightings to implement linear filtering directly in the frequency domain; for example, the formants of the human voice are conveniently impressed on the spectrum in this way (as illustrated §10.3 above) [174].11.9 We refer to the general class of such frequency-domain signal models as spectral models, and sound synthesis in terms of spectral models is often called spectral modeling synthesis (SMS).
The subsections below provide a summary review of selected aspects of spectral modeling, with emphasis on applications in musical sound synthesis and effects.