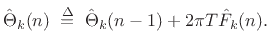In the analysis phase, sinusoidal peaks are measured over time in a sequence of FFTs, and these peaks are grouped into ``tracks'' across time. A detailed discussion of various options for this can be found in [246,174,271,84,248,223,10,146], and a particular case is detailed in Appendix H.
The end result of the analysis pass is a collection of amplitude and
frequency envelopes for each spectral peak versus time. If the time
advance from one FFT to the next is fixed (5ms is a typical choice for
speech analysis), then we obtain uniformly sampled amplitude and
frequency trajectories as the result of the analysis. The sampling
rate of these amplitude and frequency envelopes is equal to
the frame rate of the analysis. (If the time advance between
FFTs is
![]() ms, then the frame rate is defined as
ms, then the frame rate is defined as
![]() Hz.) For resynthesis using inverse FFTs, these data may be
used unmodified. For resynthesis using a bank of sinusoidal
oscillators, on the other hand, we must somehow
interpolate the envelopes to create envelopes at the signal
sampling rate (typically
Hz.) For resynthesis using inverse FFTs, these data may be
used unmodified. For resynthesis using a bank of sinusoidal
oscillators, on the other hand, we must somehow
interpolate the envelopes to create envelopes at the signal
sampling rate (typically ![]() kHz or higher).
kHz or higher).
It is typical in computer music to linearly interpolate the
amplitude and frequency trajectories from one frame to the next
[271].11.10 Let's call the piecewise-linear upsampled envelopes
![]() and
and
![]() , defined now for all
, defined now for all ![]() at the normal signal
sampling rate. For steady-state tonal sounds, the phase may be
discarded at this stage and redefined as the integral of the
instantaneous frequency when needed:
at the normal signal
sampling rate. For steady-state tonal sounds, the phase may be
discarded at this stage and redefined as the integral of the
instantaneous frequency when needed: