Our problem area is "group brainstorming". The needs we would like to focus on are portability and version control. We felt that existing methods of brainstorming using post-it notes or drawing on white boards make it difficult to re-create the session at a later time or in a different physical location. For instance, even though the sticky notes can be moved around, it is still a huge hassle to "undo" grouping actions, or to put them back into the precise arrangment made from a prior meeting session. White boards take up a lot of physical space, force team members to come to it (rather than making itself available wherever the team members are located), and are not intelligent enough to remember old notes.
By incorporating a Kinect and a projector, we could design an intelligent collaborative brainstorming interface. The Kinect would be responsible for recognizing users (based on body or facial features) and associating brainstorming actions and gestures to a specific user, which are logged in a version-tracking system. Possible input actions may include gestures for creating, modifying, categorizing, or deleting brainstormed items. Because brainstorming is a physical and social task, a gesture-based Kinect interface that does not get in the way of social communication between team members would be an appropriate approach to tackling our problem area.
Note: We've modified our problem/ application area quite a bit since Milestone 1. See Milestone 2 for a revision.
Milestone 2: Initial Prototyping - Family Bulletin Board(February 10, 2012)
Storyboarding (Hongchan)
Sketching + Video Prototype (Sukwon + Jieun)
In creating this sketch+video prototype, we wanted to learn what it would feel like to actually use this application as a family (or housemate) bulletin-board. We realized that the sensor range for the Kinect restricted the application usage space to a relatively small area, making it ideal for an open common space within a house. In creating this video, we were forced to think the extent to which Kinect should actively try to recognize and interrupt (e.g. doing an automatic biometrics scan for household-member recognition) versus wait passively until user signals for Kinect's attention (e.g. user raising hand to bring up the user's default screen and hear pending messages).
Stemming from our desire to do some biometric identification, the facial recognition feasibility test is designed to evaluate whether the kinect's low resolution camera can accurately recognize someone who is standing in front of it. By integrating with Face.com's API we are able to get a confidence interval anywhere from 1 to around 65 depending on lighting, how close you are to the Kinect, and the angle at which your face is facing the Kinect. Face.com uses a machine learning algorithm to identify people, so these numbers come after 'training' their algorithm with about 7 photos of Matt.
The code should compile and run with the standard Kinect SDK; however for this small demo the algorithm is only trained to identify Matt's face. If any member of the teaching staff is interested in trying out the recognition features we would be more than happy to train the algorithm for your face if you are able to supply a few photos of yourself. Also note we reused some of the scaffolding code given to us for p3 so the facial recognition controller is 'customcontroller1'.
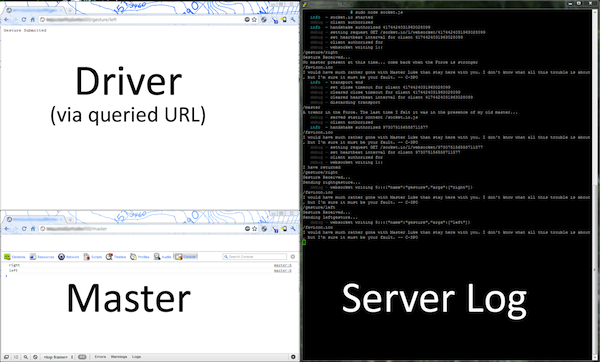
Feasibility Test: Communication between webpage and Kinect (Tyler)
Here is a prototype that demonstrates we will be able to "control" the content on a webpage via the Kinect. Basically we'll program whatever gesture recognition we need into the underlying Windows programming that we need to do, then it will try to fetch a page from our server at a URL like "www.awesome.com/gesture/left" and will then send "left" to our webpage. After receiving that message, our webpage can react accordingly, allowing us to take advantage of our friends JQuery/CSS/The Internet and save us from recreating many different wheels with WPF.
Note: need to have Node.js installed, as well as the Socket.IO plugin
Milestone 3: Wizard-of-Oz Testing - Family Member Identification(February 17, 2012)
Interface 1 - Biometric Identification
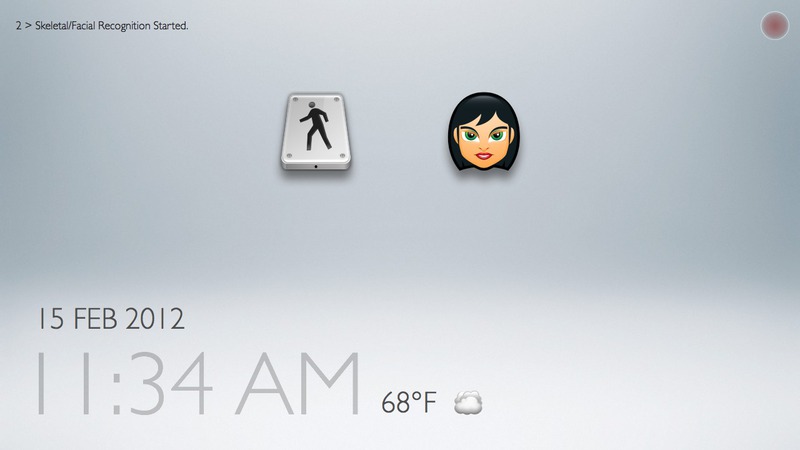
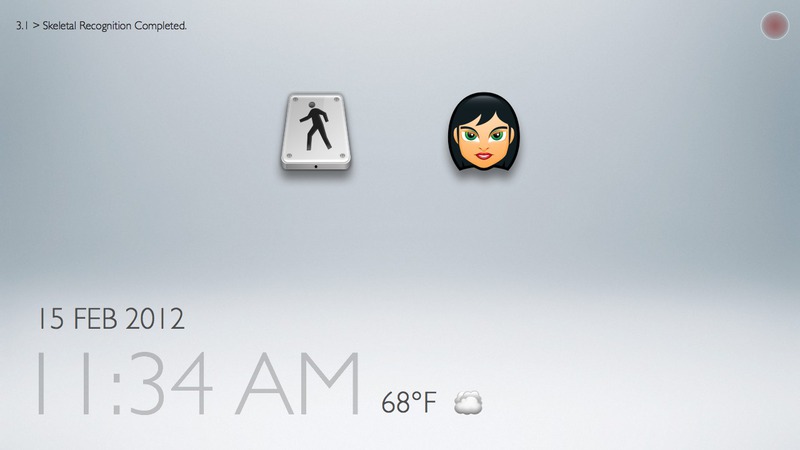
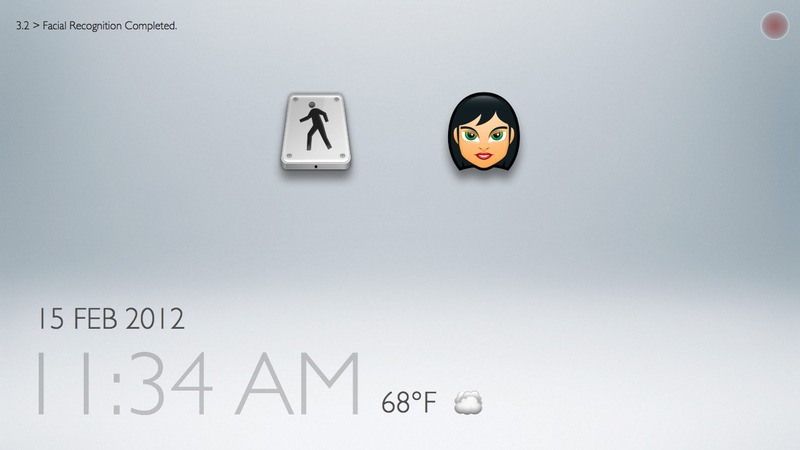
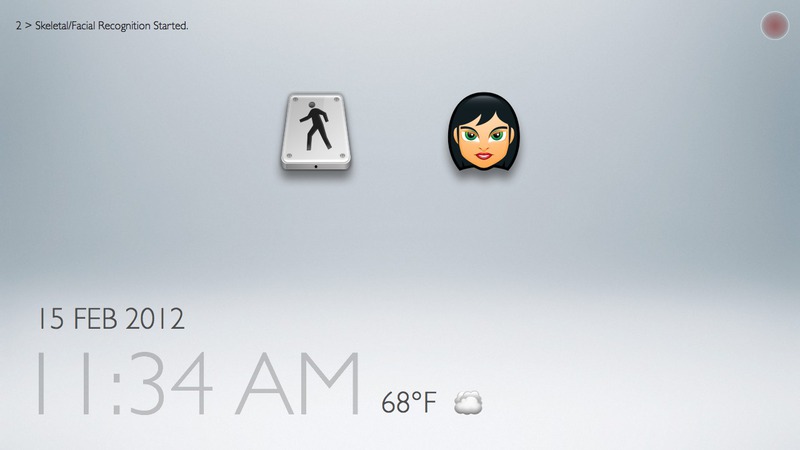
Task 1: performing skeletal and facial recognition
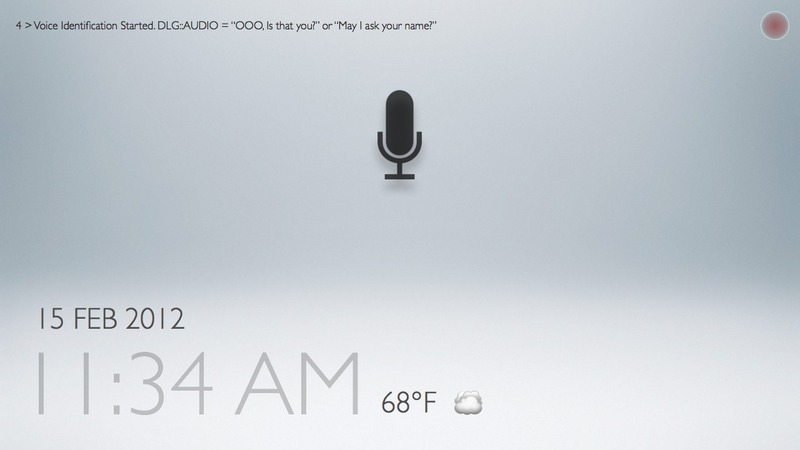
Task 2: performing voice recognition
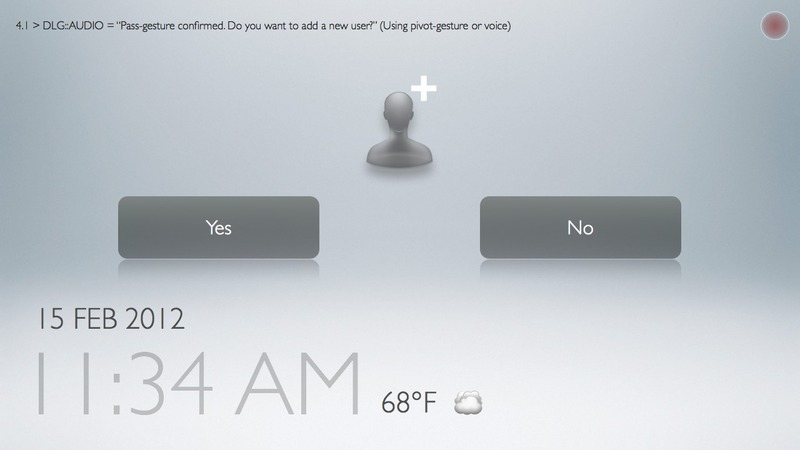
Task 3: setting gesture passcode
This interface and the associated set of tasks focus on testing the flow of interactions that would be needed during a biometric-identification phase of our "family bulletin board" application. Most of the UI flow is meant to be quick and automatic (ideally invisible to user's awareness).
Interface 2 - Unidentifiable User
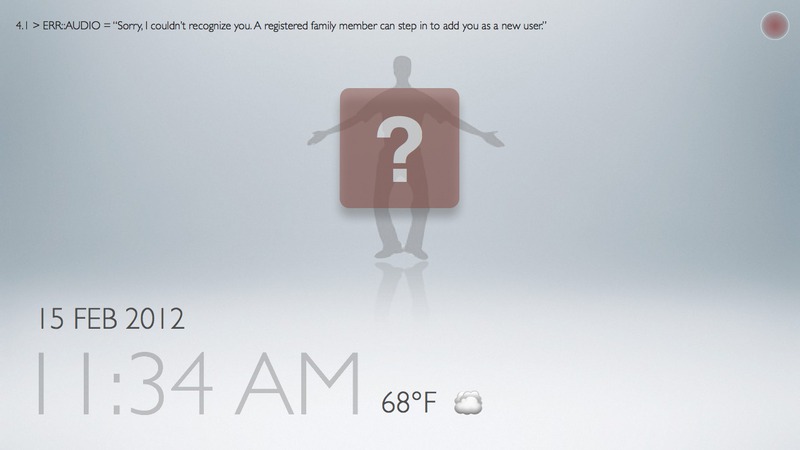
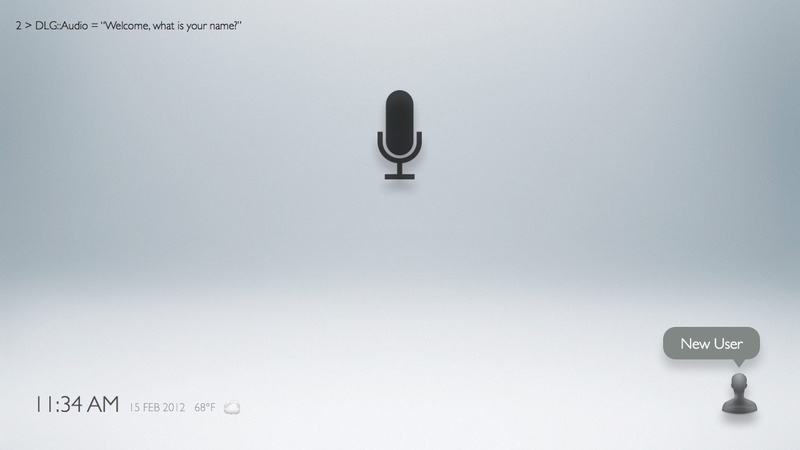
Task 1: having a registered family member step in to add a new user
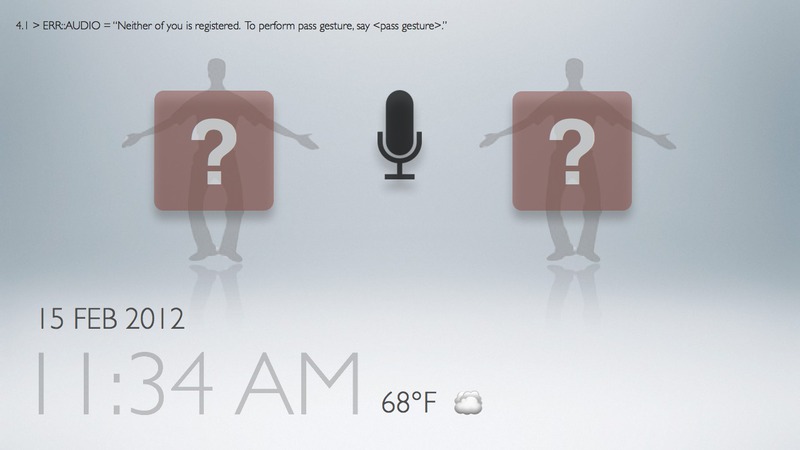
Task 2: entering gesture passcode in case skeletal and facial recognition fails
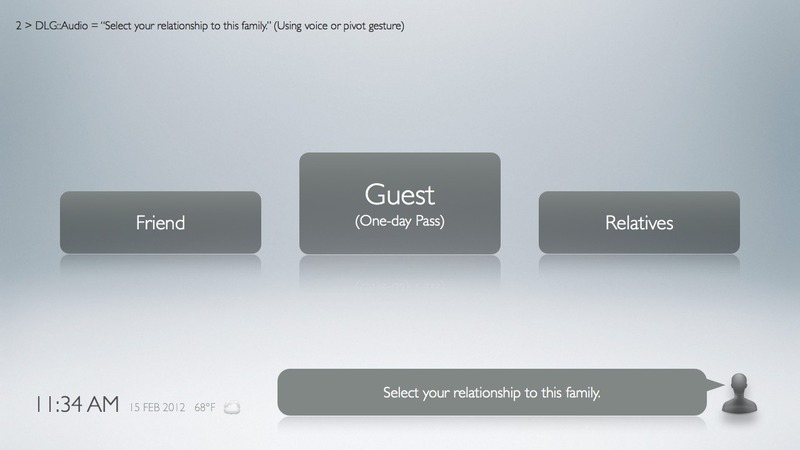
Task 3: inputting new user information: name/voice, facial profile, and family relationship
This interface looks at the special case of dealing with unidentifiable users -- whether it be because the user is not registered (e.g. guest or friend, in which case a registered family member can step in to add the user), or because the skeletal and face recognition system is not behaving perfectly (e.g. false alarm, in which case we resort to gestural passcode as a backup, analogous to "security questions" for recovering lost passowords).
Data: Sample Videos
Insightful Observations and Comments
The prompt of "May I ask your name?" is unclear:
People could respond in a variety of ways, from "yes", to "Charlton", to "My name is Charlton"
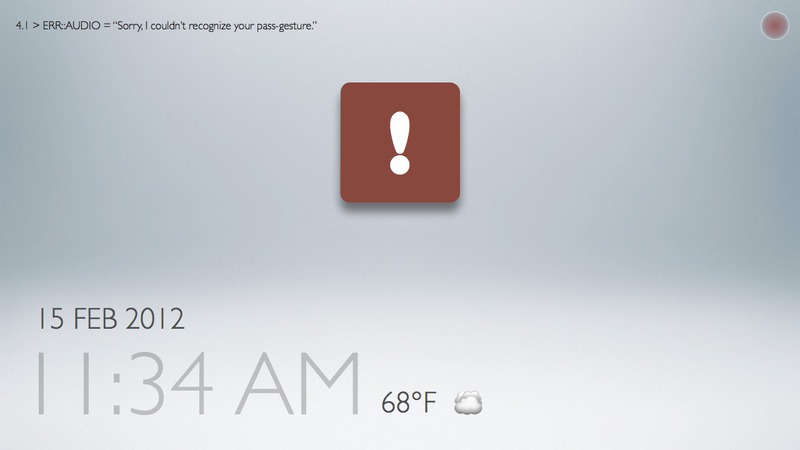
Difficulties setting a passcode gesture:
Despite the instruction, one user made a continuous trajectory between body joints, as opposed to touching discrete points in the body.
Even though we had assumed that users would touch body joints using one hand, many users used both hands, alternating between left and right hands, and occasionally using both hands at the same time (much like the Macarena).We received comments that using both hands at the same time would be less confusing and more secure.
Users had a difficult time remembering the pass gesture they had just made, resulting in a lock out. A "re-perform" gesture is definitely necessary (analogous to re-entering passwords to confirm).
"Select" gesture: without a training session on our "elbow-pivot" select gesture, users were not sure how to make a selection.
"How do I select it?"
one user just batted his hand in front of him instead of using the elbow pivot despite being prompted by teammate once to use the elbow pivot instead.
another user tried pointing gestures to try and cycle through a list
Feedback from Rob regarding use of icons for skeletal and facial recognition status:
"People don't want to know the details of the system. Across cultures people raise eyebrows and eye contact to initiate exposure"
Feedback from Jeff regarding system's personality:
Have it be more conversational in a less system way… Casually receive the information needed from the user.
"can you design such that you are doing authentication in a secure way without feeling like it? My computer has a different conversation with me everyday… identify without making it feel like it. Where is the interaction experience and how do you make it different?"
Larger-Scale Reflections and Directions for Future
How much authentication do people want in their home? Taking time to "authenticate" may become an annoyance
Shift focus from "authentication" to "identification". Assuming that our application will be used in a livingroom, we can probably assume that the members accessing this application can be "trusted". Thus, the focus will be on classifying users as a known family member (with some confidence interval), as opposed to rejecting a user who is suspected of being an intruder.
Displaying private/personal content vs. tailored social content
The focus on content to be displayed should be on aggeregating information appropriate for the "social" setting (given the people who are present in the space), as opposed to displaying personal and private information. Again, this is related to the form-factor of our application: we felt that "personalized content" makes more much more sense on hand-held platforms, but not the living room.
Collaborative gestural input?
Pushing this idea that the living room is a common (social) space, we feel that it would be very appropriate for our application to handle collaborative gestural input. We hope to realize this idea by allowing two people to, for instance, shift between independent browsing and shared browsing mode.
Milestone 4: Prototype I (February 24, 2012)
Features & Rationale
Overarching Concept: 10-feet space
Our user interface should be suitable for very specific setting: the living room. We believe that the experience in the living room should be different in many ways than the close-distance user experience on a laptop, desktop or tablet. All the GUI elements are designed with this principle in mind.
Gesture Analyzer (Kinect, C#)
Pivot gesture for browsing items: Most of the gestures we brainstormed were not practical and caused muscle fatigue even in a short amount of time; we felt that "pivoting" is the most compact and efficient way to browse multiple objects (see our group’s P3 Elbow-Pivot controller).
Hand raising gesture for selecting the menu: After browsing items with elbow pivoting, a user can select the item by raising his hand. By adding this separate selection step, user has a chance to correct actions in case the system does not respond cleanly.
Confirm with a "slash"; Cancel with an "X" gesture: In the confirmation step, user can either finalize their selection by performing a "slash" gesture or reject previously selected item by making "X" gesture. These are gestures fundamental to navigating in our system, and we felt that the "slash" and "X" motions were quick and intuitive to perform.
Back-End (NodeJS)
"Web > C#": Choosing to use NodeJS to tie in the Kinect with a webpage gives us an incredible amount of flexibility over the content we display, how it is displayed, and how easy it is to get real data on the page. If we had chosen to do our UI in WPF, so much more pain would have been experienced on our part and we probably would have started to cry…
Front-End Web Application (HTML, CSS, Javascript, JQuery)
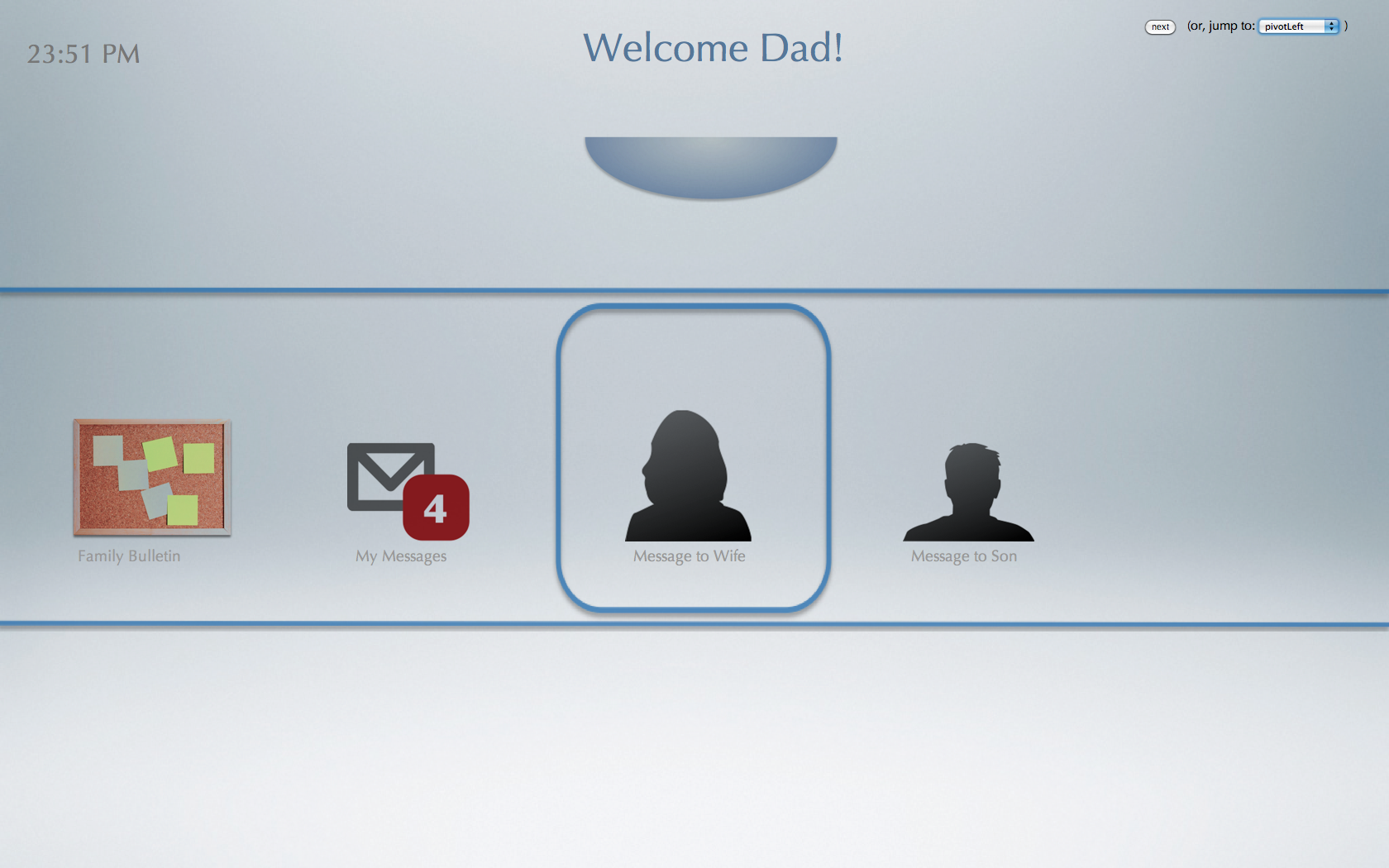
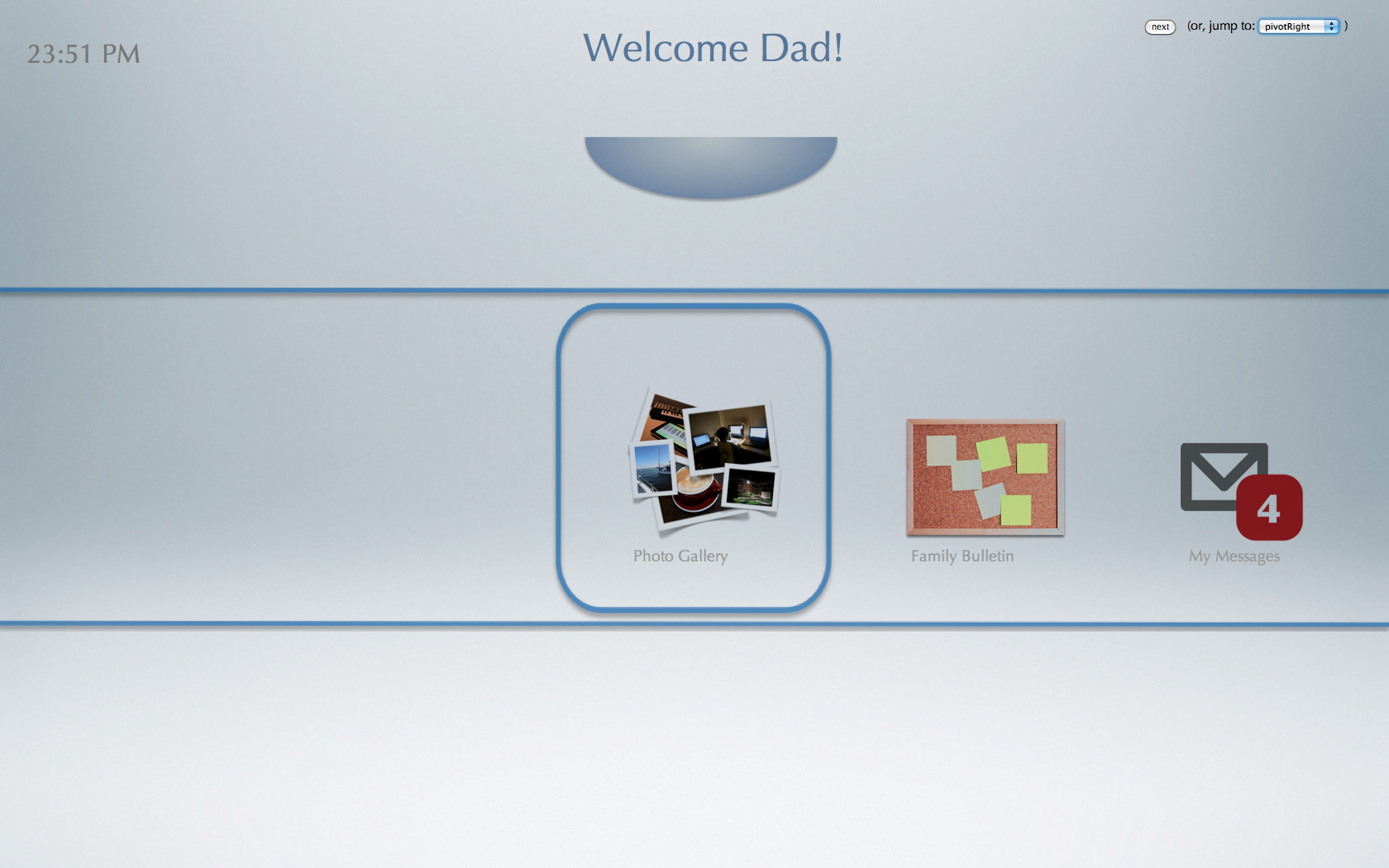
Our front-end web application interface currently handles the following stages of our application. These stages were chosen because they are the initial steps required in the usage flow of our living-room application.
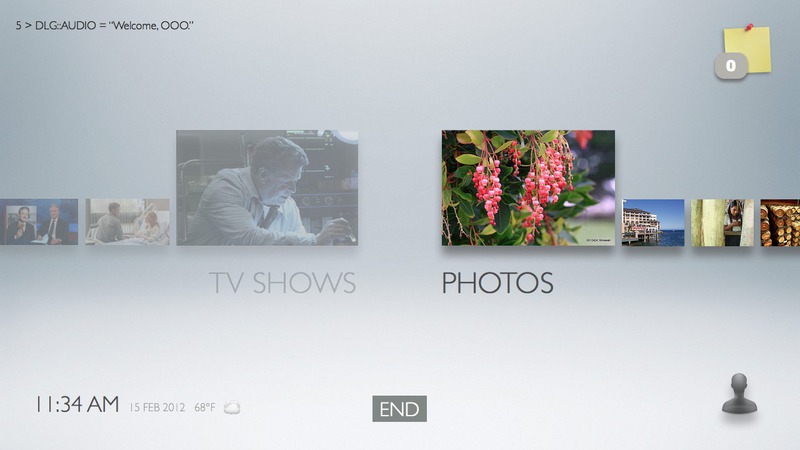
default page showing family pictures - when no user is in the proximity
member identification phase - for when a user steps into Kinect’s sensing range
menu navigation - using elbow-pivot gesture to browse and select from options (such as to send a video message to a family member, or to view or browse the family bulletin board)
recording a 10-second video message (current implementation is just the animation, and does not yet actually record the video…)
For the gesuter analyzer, we are using a custom application built with XNA and KinectSDK, and it sends HTTP requests to trigger the change of user interface through NodeJS, which then calls different javascript functions running in our front-end web application. The one of advantage of this configuration is we can separate development processes into two areas - "gesture detection/debugging" and "GUI design."
Gesture Analyzer (Kinect, C#)
The elbow-pivot browse gesture, hand-raising select gesture, "slash" confirm gesture, and "X" cancel gestures were implemented. When we were testing our own gesture implementations, it worked quite well since we knew how our analysis code worked. In the studio session, however, we found that users used a whole variety of gestures, some of which could not be recognized properly, despite our instructions. Also, we found some people trying random gestures based on their own experiences with smart phone or other existing products.
Back-End (NodeJS)
The underlying NodeJS code is in place and is ready to accept any new feature(s) we throw at it that come to mind. Adding a view that displays primary joints currently being used by the user is in the works and is currently undergoing a feasibility test - if that is even the way we want to go.
Front-End Web Application (HTML, CSS, Javascript, JQuery)
Our front-end web application is implemented using standard HTML, CSS, Javascript, and JQuery. The 4 major features described above (default page, member identification phase, menu navigation, and video recording) have been encapsulated by a series of javascript functions:
showDefault(); // default screen with floating photos and current time
identifying(); // when Kinect notices that someone is in its proximity and is identifying who the person is
identified( user_id ); // when Kinect identifies user of id user_id
unidentified(); // when Kindect fails to identify -- goes into default guest mode (not fully implemented yet)
showMenu( user_id ); // shows menu for the user -- called automatically after ~1 second once the user has been identified
pivotLeft(); // menu items translate one to the left
pivotRight(); // menu items translate one to the right
pivotSelect(); // selects item in the center of menu.
startMessage(); // begins recording video memo
stopMessage(); // by up message
pushMessage(); // pushes message to the recipient’s folder during preview view
List of Remaining Issues
Completing the Architecture
We need to add the "Media database" component and it will be responsible for storing and fetching image data in real-time.
Gesture Analyzer (Kinect, C#)
Despite our careful designing of the “elbow-pivot” controller, many users in the studio session tried to apply gestures from touchable screen, resulting in frequent failures in recognizing the pivoting gesture. We need to further explore this issue during our user-testing, and modify our implementation (either by tweaking the gesture analyzer code, or by introducing a feedback to guide users to correctly use our set of gesture).
Back-End (NodeJS)
We found that one of the shortcomings associated with our architecture is that users do not get a feedback of their gestures. Perhaps the (x,y,z) position of the joints should be propagated from the gesture analyzer through NodeJS to the front-end application (continuously, in “real-time”), so that we have at least a simple visual display of what the system thinks the user is doing.
Front-End Web Application (HTML, CSS, Javascript, JQuery)
Currently implemented features only deals with the initial steps in the usage flow of our application. Depending on which area we end up focusing in (e.g. bulletin board vs. recording media messages vs. browsing recorded messages), we’ll need to implement the front-end for that area.
Note to teaching staff: If you'd like to view s1_1.mov, s1_2.mov, s1_3.mov, and s1_4.mov (as alluded to in our write-up), please contact us. We removed the links to protect subjects' privacy. Thanks!
collage.m4v(may need to download then watch if format is not compatible with browser or if connection is slow
Milestone 6: Prototype II (March 12, 2012)
UI States [with auditory feedback implemented in ChucK]
Idle
[ idle.wav ]
default state, when no one is in front of Kinect (or if user steps out of its proximity)
Identifying
[ identifying.wav ]
when user stands in the proximity of Kinect, Kinect tries to identify the user (currently wizard-of-ozed)
Identified
[ identified.wav ]
once family member has been identified, application displays a photodesk (analogous to desktops; comprising of "spaces" of quadrants of photo tag clusters)
Browsing
[ dx=1 | dx=3 | dx=7 | dx=-1 | dx=-3 | dx=-7 ]
allows users to browse photos in the selected tag album (arranged in a linear menu), using swipe gestures
scroll forward or backward in 3 speeds: slow (dx=1), medium (dx=3), fast (dx=10)
scroll animation for visual feedback, showing dx items translating with physics
event-based auditory feedback: frequency bulge-up for forward, bulge-down for backward navigation; temporal duration and frequency amount of the bulging trajectory is dependent on dx
Rating
[ begin | 1-star | 2-stars | 3-stars | 4-stars | 5-stars ]
user can rate a photo (while in browse mode) giving 1-5 stars, by raising right hand vertically above left hand at torso level
Universal
user is in range (presence icon: gray)
user is at the sweet spot (presence icon: green)
user is out of range (remove presence icon)
Implementation Details
Tech Doc (pdf) communication specification for Kinect C# application, NodeJS, photo database, and front-end web app (javascript)
Remaining Issues
polish gesture control implementation for photo rating
tweak auditory feedback design and timing to fit animations
improve skeletal-based member identification (beyond wizard-of-oz)
test mobile-app for uploading and tagging photos to database for demo