bio
research
publications
résumé
Below I describe a few representative examples of recent work, along with some illustrative images, demonstrative sounds/videos, etc. Feel free to contact me for further material.
DYNAMIC VISUALIZATION OF RHYTHMIC LATENT SPACES

R-VAE is a system designed for the modeling and exploration of latent spaces of musical rhythms. R-VAE employs a data representation that encodes simple and compound meter rhythms, common in some contemporary popular music genres. It can be trained with small datasets, enabling rapid customization and exploration by individual users. To facilitate the exploration of the latent space, R-VAE is powered with a web-based visualizer designed for the dynamic representation of rhythmic latent spaces.
https://zenodo.org/record/4285422
SIMULATION OF HEAD RELATED TRANSFER FUNCTIONS

Through a modified state-space filter structure allowing a time-varying number of inputs, it is possible to efficiently simulate the minimum-phase part of head related transfer functions (HRTF) at low computational cost, no convolution, while allowing for perceptually motivated warped frequency resolutions and reception of multiple wavefronts of time-varying direction. In the left plots, modeled HRTF spectra designed over linear frequency resolutions. In the right plots, modeled HRTF spectra designed over warped frequency resolutions. Top to bottom plots, increasing modeling order: 8,16,32.
https://hal.archives-ouvertes.fr/hal-02275169
SIMULATION OF SOUND SOURCE DIRECTIVITY

Through a modified state-space filter structure allowing a time-varying number of outputs, it is possible to simulate sound source directivity at low computational cost, no convolution, within geometric acoustic frameworks. With applicability in sound synthesis and/or auralization within virtual environments where sound sources change position and orientation dynamically, directivity profiles can be modeled on perceptually motivated warped frequency axes, with alternatives for representing directivity on a per-vibration-mode basis or by reduced-order efficient representations. In the right plots, spectra of the radiation transfer function of a rotating violin and clarinet (top: measured; bottom: simulated).
https://hal.archives-ouvertes.fr/hal-02275169
AUTOMATIC PERFORMANCE ON PHYSICAL MODELS
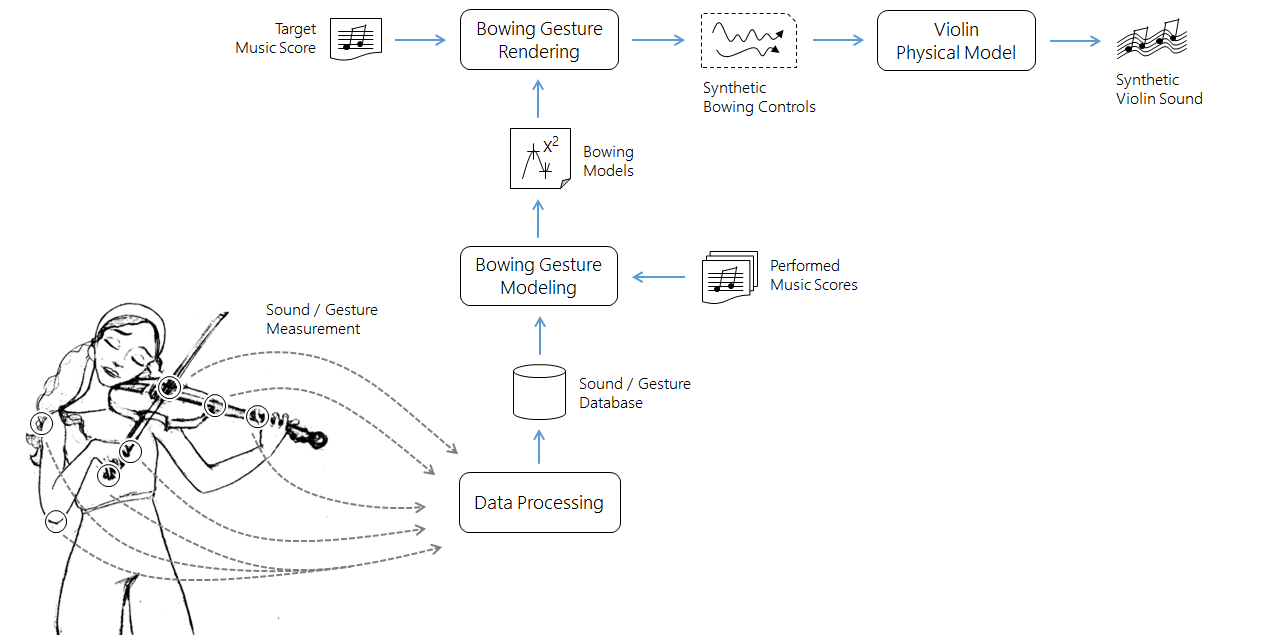
Through synthetic bowing control signals rendered from an annotated traditional score via a generative model trained from motion capture data, it is possible to drive a fairly simple bowed string physical model to obtain natural-sounding expressive violin performances:
REAL-TIME INTERACTIVE CONTROL OF PHYSICAL MODELS

By coupling digital waveguides and modal synthesis it is possible to construct highly efficient, yet realistic physical models ready for interactive control. At the link below it is possible to watch and illustrative example of violin synthesis model controlled via a laptop trackpad. The model, which uses less than 5% of the CPU power of a 2013 Macbook Air, incorporates a thermal friction model implemented via a one-dimensional finite-difference scheme coupled to the bow-string nonlinear interaction mechanism:
EFFICIENCY OF HYBRID PHYSICAL MODELS

To illustrate the effciency and fidelity offered by coupling modal synthesis and digital waveguides, a example of synthetic guitar string plucks is provided here. The model, constructed from automated processing of a fairly reduced set of simple vibroacoustic measurements on an acoustic guitar, emulates the 2D motion of 6 strings, string-string coupling, string-body coupling, and body radiativity. In one core of a 2013 laptop, it is possible simultaneously run about 40 of such models:
MODAL REVERBERATION
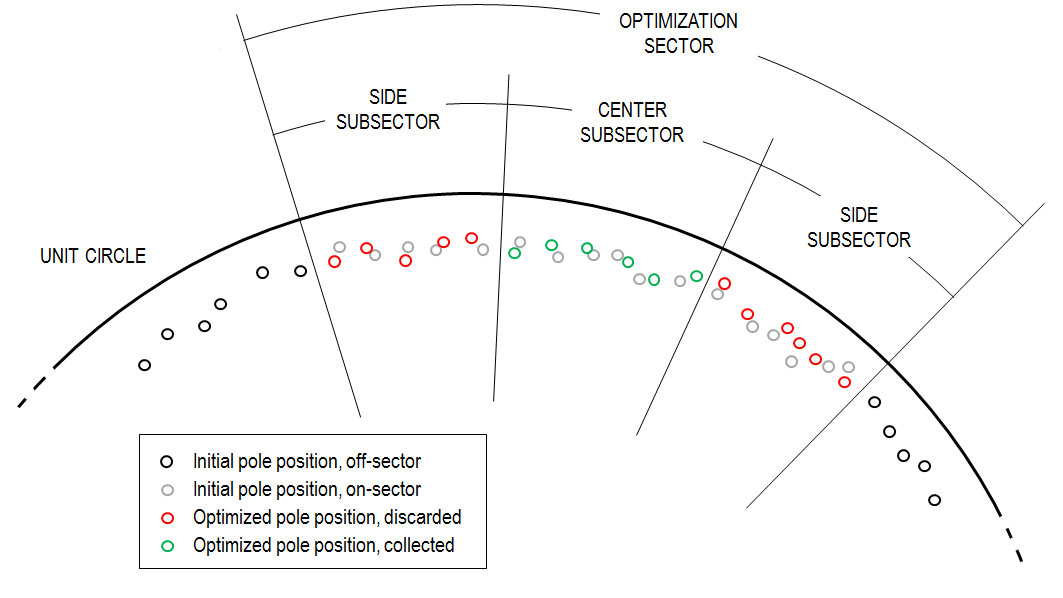
Modal reverberation offers great advantages: efficiency, flexibility, zero-delay, parallel implementation, etc. Moreover, it supports a dynamic representation of a space, at a fixed cost, so that one may simulate walking through the space or listening to a moving source by simply changing the coeffcients of the fixed modes being summed. Below I point to a few examples of static reverberation models obtained via a pole optimization technique presented at DAFX 2017:
http://ccrma.stanford.edu/~esteban/modrev/dafx2017
MULTIMODAL ANALYSIS - RESEARCH REPRODUCIBILITY

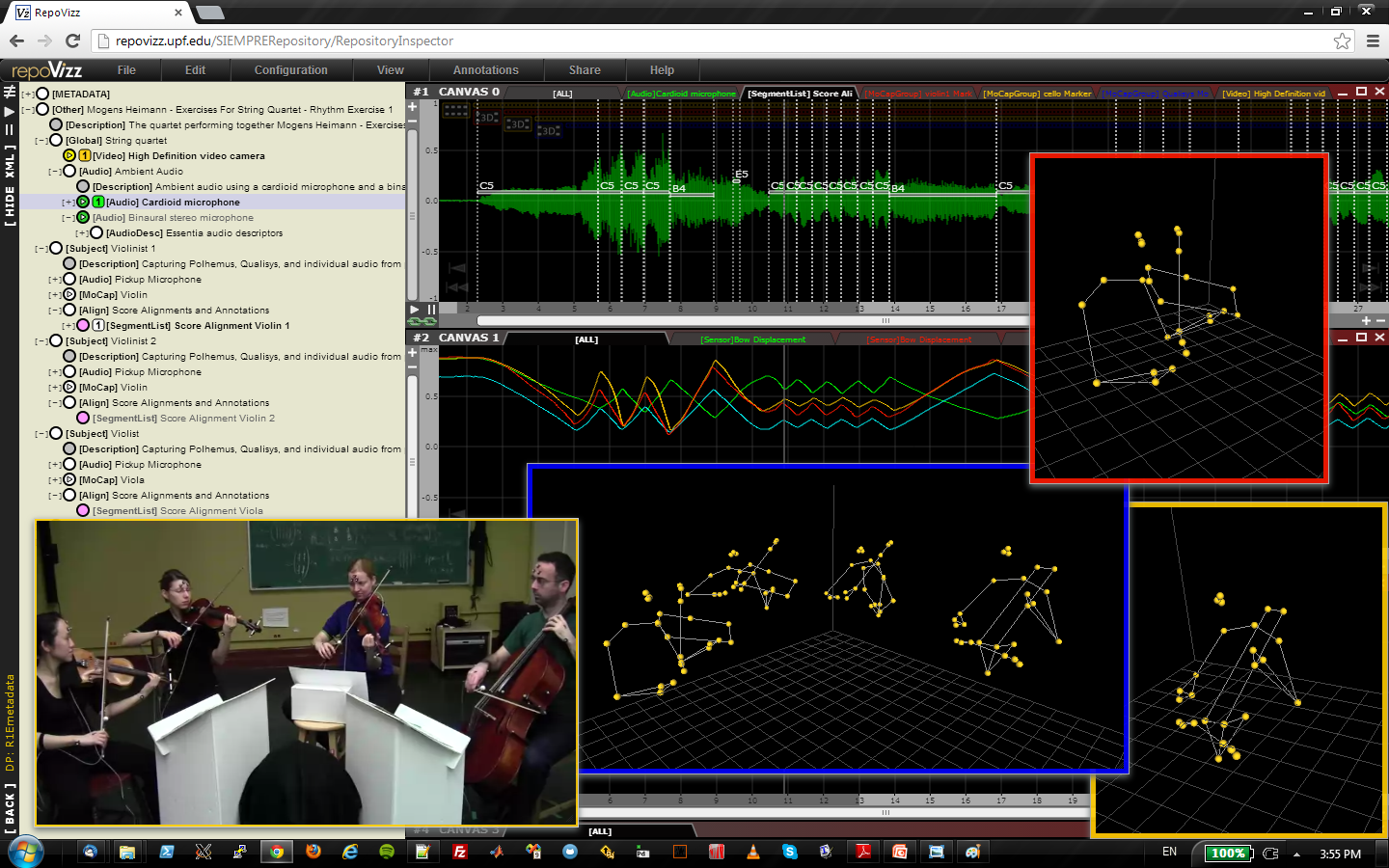
In the context of string quartet performance analysis, I envisioned, promoted, and led the development of Repovizz. The Repovizz system comprises a remote hosting platform and a data archival protocol through which data of different modalities can be stored, visualized, annotated, and selectively retrieved via a web interface and a dedicated API. A video demonstration and the project website can be respectively accessed at:
http://repovizz.upf.edu
DYNAMIC VISUALIZATION OF RHYTHMIC LATENT SPACES
R-VAE is a system designed for the modeling and exploration of latent spaces of musical rhythms. R-VAE employs a data representation that encodes simple and compound meter rhythms, common in some contemporary popular music genres. It can be trained with small datasets, enabling rapid customization and exploration by individual users. To facilitate the exploration of the latent space, R-VAE is powered with a web-based visualizer designed for the dynamic representation of rhythmic latent spaces.
https://zenodo.org/record/4285422
SIMULATION OF HEAD RELATED TRANSFER FUNCTIONS
Through a modified state-space filter structure allowing a time-varying number of inputs, it is possible to efficiently simulate the minimum-phase part of head related transfer functions (HRTF) at low computational cost, no convolution, while allowing for perceptually motivated warped frequency resolutions and reception of multiple wavefronts of time-varying direction. In the left plots, modeled HRTF spectra designed over linear frequency resolutions. In the right plots, modeled HRTF spectra designed over warped frequency resolutions. Top to bottom plots, increasing modeling order: 8,16,32.
https://hal.archives-ouvertes.fr/hal-02275169
SIMULATION OF SOUND SOURCE DIRECTIVITY
Through a modified state-space filter structure allowing a time-varying number of outputs, it is possible to simulate sound source directivity at low computational cost, no convolution, within geometric acoustic frameworks. With applicability in sound synthesis and/or auralization within virtual environments where sound sources change position and orientation dynamically, directivity profiles can be modeled on perceptually motivated warped frequency axes, with alternatives for representing directivity on a per-vibration-mode basis or by reduced-order efficient representations. In the right plots, spectra of the radiation transfer function of a rotating violin and clarinet (top: measured; bottom: simulated).
https://hal.archives-ouvertes.fr/hal-02275169
AUTOMATIC PERFORMANCE ON PHYSICAL MODELS
Through synthetic bowing control signals rendered from an annotated traditional score via a generative model trained from motion capture data, it is possible to drive a fairly simple bowed string physical model to obtain natural-sounding expressive violin performances:
REAL-TIME INTERACTIVE CONTROL OF PHYSICAL MODELS
By coupling digital waveguides and modal synthesis it is possible to construct highly efficient, yet realistic physical models ready for interactive control. At the link below it is possible to watch and illustrative example of violin synthesis model controlled via a laptop trackpad. The model, which uses less than 5% of the CPU power of a 2013 Macbook Air, incorporates a thermal friction model implemented via a one-dimensional finite-difference scheme coupled to the bow-string nonlinear interaction mechanism:
EFFICIENCY OF HYBRID PHYSICAL MODELS
To illustrate the effciency and fidelity offered by coupling modal synthesis and digital waveguides, a example of synthetic guitar string plucks is provided here. The model, constructed from automated processing of a fairly reduced set of simple vibroacoustic measurements on an acoustic guitar, emulates the 2D motion of 6 strings, string-string coupling, string-body coupling, and body radiativity. In one core of a 2013 laptop, it is possible simultaneously run about 40 of such models:
MODAL REVERBERATION
Modal reverberation offers great advantages: efficiency, flexibility, zero-delay, parallel implementation, etc. Moreover, it supports a dynamic representation of a space, at a fixed cost, so that one may simulate walking through the space or listening to a moving source by simply changing the coeffcients of the fixed modes being summed. Below I point to a few examples of static reverberation models obtained via a pole optimization technique presented at DAFX 2017:
http://ccrma.stanford.edu/~esteban/modrev/dafx2017
MULTIMODAL ANALYSIS - RESEARCH REPRODUCIBILITY
In the context of string quartet performance analysis, I envisioned, promoted, and led the development of Repovizz. The Repovizz system comprises a remote hosting platform and a data archival protocol through which data of different modalities can be stored, visualized, annotated, and selectively retrieved via a web interface and a dedicated API. A video demonstration and the project website can be respectively accessed at:
http://repovizz.upf.edu