The name is partially derived from the idea of mashing up songs, except the method I use can vary from unintelligibly small to slightly longer and more intelligible snippets which may or may not give it an acerbic flavor. The other reason is that sour mash is one method used to produce a tasty beverage. I also like to think about this synthesis/exploratory process as a "distillation" of sorts.
The sour mash spun out of my desire to better understand feature representations of music. MIR researchers have found that by incorporating larger and larger feature sets, performance on classification and retrieval tasks increases. While this is not all that surprising, I've been frustrated by the kitchen-sink approach to analyzing music. These may outperform other, more elegant approaches, but I believe that if we better understand the current limitations of our features sets we will be able to build better features. This project is an attempt to illuminate what information is actually captured by widely used feature representations of music. And I think I may have stumbled across a pretty cool way to make music.
My initial goal was to create a database of short snippets of audio that would then be used to re-synthesize an input track in real time. Ignoring the difficulty of real-time audio, I began by extracting 20 MFCC (Mel Frequency Cepstral Coefficients) and storing them in a Sqlite database. Then I tried to read in a new track, extract 20 MFCCs over the audio buffer, query the database for the closest match, and pull audio from the database song into the output buffer. This was a miserable failure. Every single aspect of the system was too slow. Like Michelangelo chiseling David out of a 9 foot tall piece of marble, I began paring down the system I started with until it was functional in real time.
The final system uses a database of a whopping 10 database songs and 5 features. Sour Mash extracts the first 5 MFCCs from a windowed, overlapping audio buffer, and each track is analyzed using 5 different buffer lengths. Because speed's the name of the game, I abandoned my beloved Python in favor of C++ and several excellent libraries. I used libxtract to extract MFCCs, libsndfile to read (and eventually write) audio files, and Soci to connect to the Sqlite database. To speed up querying the database, I implemented a variation of Sqlite that indexes rows through a range query, (typically used for spatial searches.) Each search automatically starts with a "small" bounding box in the feature space, and gradually expands the search until it finds a match. I chose to implement the search this way because the database is able to perform several queries that return a small number of matches much faster than it is able to perform a single query that returns a large (>20) number of matches. I used JUCE to simplify incorporating buttons, sliders, boxes, and OpenGL.
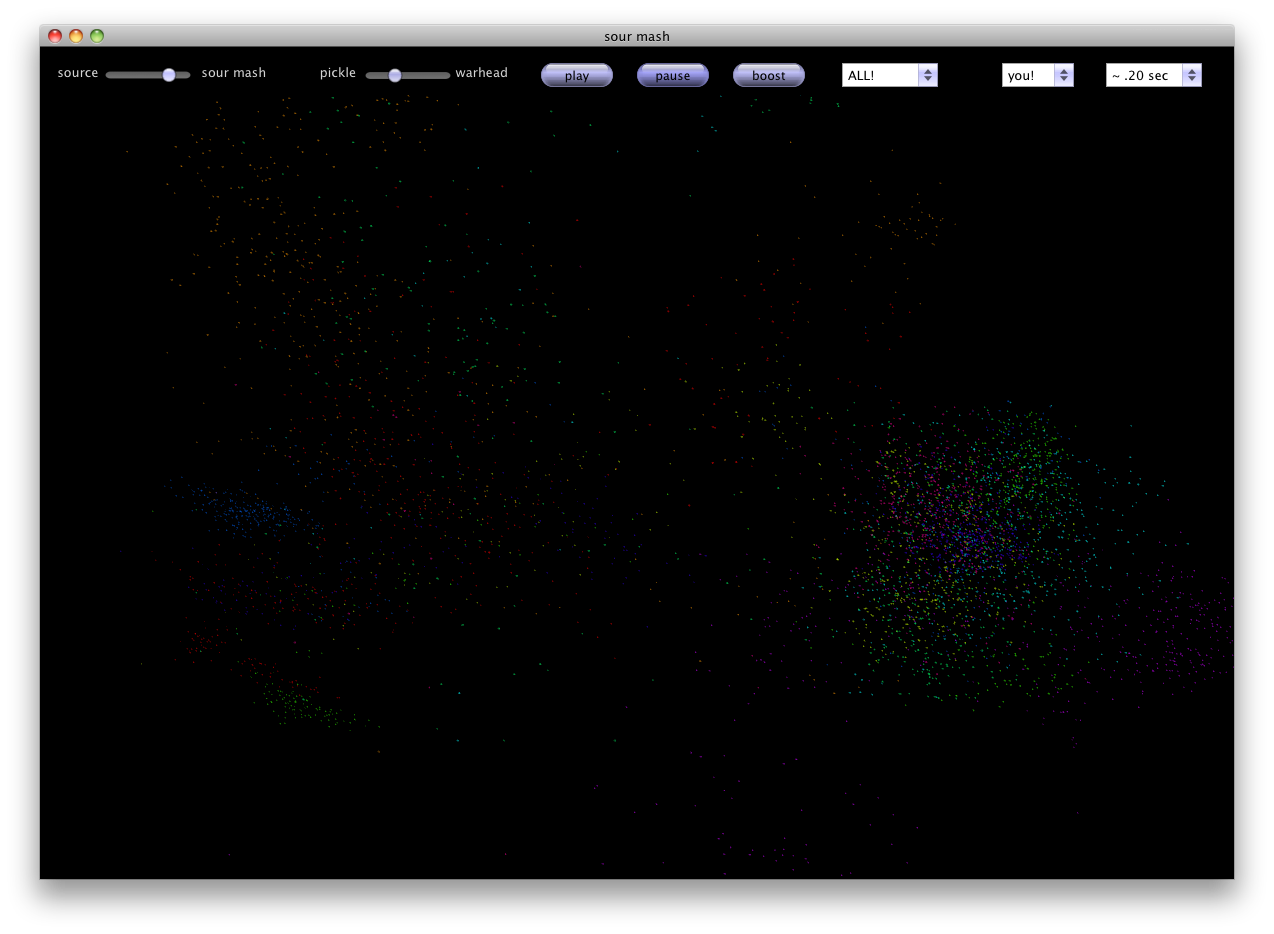
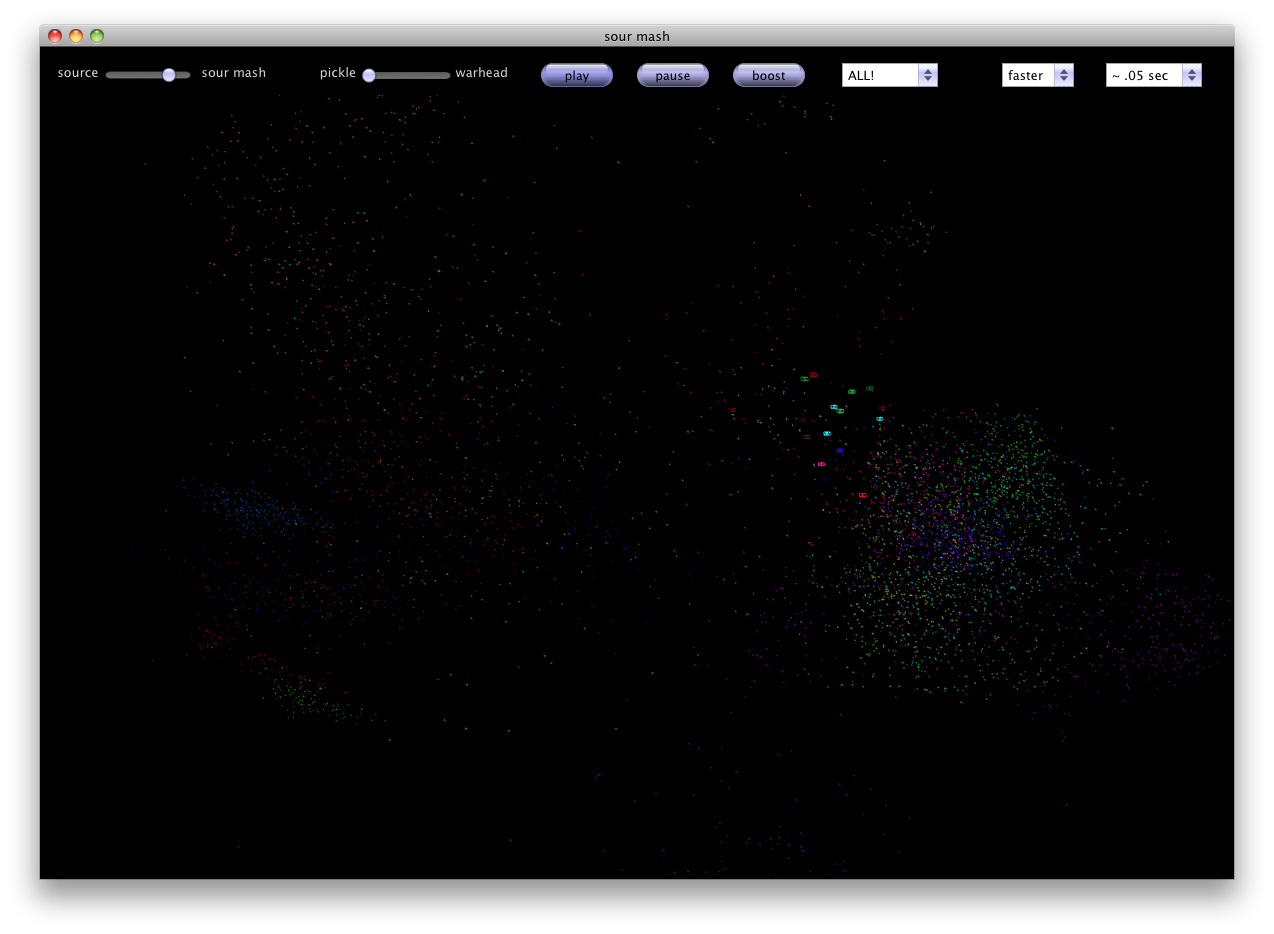
The program controls are located at the top of the window. There is a slider from 'source' to 'sour mash' that acts like a dry-wet mixer. Source is the input track and sour mash is the resynthesized version. The 'pickle' to 'warhead' slider controls how sour the mix is. Querying the database with the right range is a finicky process. It's hard to find the optimal range to use be searching for points in the DB. If the range is too narrow, you won't find anything. If it's too large, the audio buffer slows down. The sour slider is used to increase the range around the source point to search in the feature space. The three buttons control playing the audio, pausing the audio, and a super secret speed hack in which I cheat and play each clip twice as long to avoid returning empty audio buffers when the search takes too long. To the right are three dropdown boxes. The first allows you to select which audio track(s) you want to use as the database tracks, the next box selects the input track (you can also resynthesize the mic input), and the third controls the size of the buffer to use. Below the control bar is a visualization of the first three MFCCs of the database tracks. Up to 5,000 buffers from each database track are plotted in a normalized 3-d space as dim dots. During resynthesis, each matching frame is plotted as a bursting dot in the feature space that dies out over time.
I've found that the best way to find an interesting mix is to start with the sliders at 'source' and 'pickle' so you're hearing only the input track. You then slide the sour slider until the input track starts to stutter a little. This is because the range is just large enough that the database query is returning a couple dozen matches. Now back off the sour slider a little bit (so the buffer isn't stuttering anymore) and move the mix from source toward sour mash. Depending on the buffer size you're using, you may be able to hear drum hits that align with the input track, or snippets with a similar feel.
As I hinted in my demonstration (by sampling Getting Better by the Beatles, Faster by Janelle Monae, and Stronger by the Kanye West,) it needs to be better, faster, stronger. Mostly faster. If I was a little smarter about threading, about overlap adding, and if I got my database up to snuff, this could be much more compelling. I considered getting rid of the database altogether and implementing some sort of tree or multidimensional data structure, but with the number of features I'd ultimately like to incorporate (100+), I think that locality sensitive hashing would be ideal. In its current form, it would benefit from some sort of dimension reduction algorithm (PCA would've been nice) to be able to incorporate more features without sacrificing speed. From a more experiential standpoint, interaction with the visualizer could allow the user to actively explore the feature space. Some ideas are to provide ways for the user to sonify samples, clusters of samples, or even synthesize new pieces by drawing paths through the feature space. The potential for sprawl is endless.
you can check out my progress on the next incarnation of sour mash here
Here's a little bit of the code. Holler if you want the full xcode project.