The pre-masking is too short to be exploited in the same way as in post-masking, but it is still important. Pre-masking comes in useful to hide the effect of pre-echos, which can become audible in transient sounds. Pre-echos comes from the fact that quantized transform coefficients produce noise in all time instants in the time domain. A quiet signal block with a transient in the end (e.g a drum) will thus be noisy even before the transient, where it can be heard. By making the transform blocks short enough, this effect can be hidden by the pre-masking.
In this coder, the audio is transformed in 512-length MDCT blocks (11.6 ms), every 256 samples (5.8 ms). This is not enough to hide pre-echos at all times, see section 5.
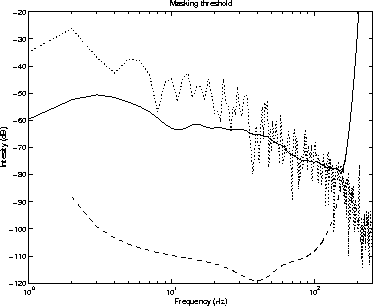
Figure 5: An example of the masking threshold produced by the
psychoacoustic model in the coder. The example
frame is number 500 (after 2.9 s) in sample jacob.wav.