Note: the sound examples are HUGE
Now we also have MPEG audio sound examples. MPEG playback utilities available at
ftp://ftp.iuma.com/audio_utils/mpeg_players/. These mpgs are encoded at 128kbits/sec, which may be quality overkill on some of these sounds.
Notes on Chris Chafe's Nov. 14 Lecture
Short title: "What Makes Synthesis Difficult."
Intro Sound:
Bagpipe example by additive resynthesis
[Bagpipe.wav (1.9MB)]
(mpg, 688kB)
Review (of concepts from Tuesday, Nov-12's lecture)
Sound generation by computer is accomplished by three classes of techniques. A "photographic" replica of a sound or recording can be digitized and played back. Isolated snippets of tones or phones can be concatenated to create a montage of music or speech. Smooth transitions between snippets are difficult and modification is limited to pitch change (with artifacts), filtering or amplitude contouring. Spectral techniques provide a canvass for painting sounds sine-by-sine up to the limits of the analysis of a sound. Choice of additive or FM techniques dictate the kind of "brush" resolution possible. Subtractive synthesis is like an eraser. Physical modeling techniqus give more realistic transitions and controls by imitating the physics of vibrating sound sources mathematically.
Sound-based Interfaces
Speech synthesis and recognition, though available are not yet in widespread use. The quality of synthesis results in a machine with an electronic accent, something which has been put to good use in the movies to portray the ego of a computer character, eg. HAL in 2001, who sings
[DaisyBell.wav (1.7MB)]
(mpg, 628kB)
(example provided by Max Mathews from early work at Bell Labs). The quality of a singing character can make lasting impressions. Spectral synthesis of the Queen of the Night aria
[rodet.wav (8.2 MB)]
(mpg, 746kB)]
from Mozart's Marriage of Figaro captures many features of a soprano when synthesized spectrally (example by Xavier Rodet, IRCAM).
An example of traditional Greek chant provided by Perry Cook
[GreekShiela.wav (3 MB)]
(mpg, 1.1 MB)
provokes a memorable image, in this case simulated through a physical model of the singer's vocal tract driven by extremely detailed controls.
Subtleties such as the quality of reflected light in a synthetic image, or vibrato in an FM vocal synthesis often constitute the determinant in our perception of an intended identity. Vocal synthesis emerging from a steady organ tone depends only on the addition of vibrato. The trick here is that the organ tone contains the appropriate sine mixtures for the formants of a vowel. Vibrato provides the ear with enough tracing of the formant shape to make it salient
[chowning.wav (18.7 MB)]
(mpg, 1.7MB)
(example by John Chowning).
Timbre
Timbre is a multi-dimensional attribute that gives rise to the identity of a sound source. And further describes the particular nuances of quality that the source is capable of making (eg. male voice, "ahh" vowel). John Grey investigated timbre differences for his dissertation in Psychology at Stanford in 1976. Figure 1 portrays the analyzed spectra of a clarinet tone in two ways, as a time, freq, amplitude plot and as a 2-d spectrogram.
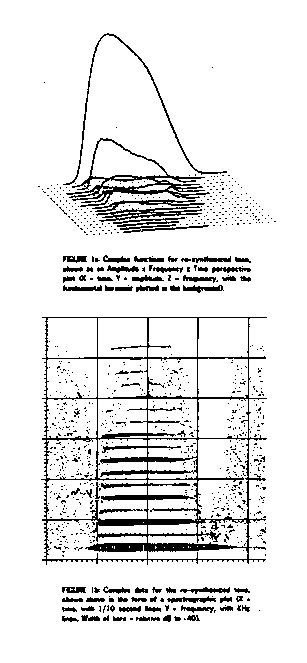
Figure 1: Two spectral views of a clarinet tone.
The tone's individual spectra can be heard first in isolation
[greyCl-1.wav (5 MB)]
(mpg, 452kB)
and then in increasing combinations to rebuild the original
[greyCl-2.wav (3.4 MB)]
(mpg, 313kB)
. Other instruments of the orchestra were analyzed at the same pitch and a solution to their similarity found through careful listening judgements. Three dimensions were sufficient to describe salient acoustic cues and are shown in two 2-d matrices: figures 2 and 3. Figure 4 shows the data in 3-d leading to a synthesis of in-between points
[greyInterp.wav (11 MB)]
(mpg, 1.0MB)
.
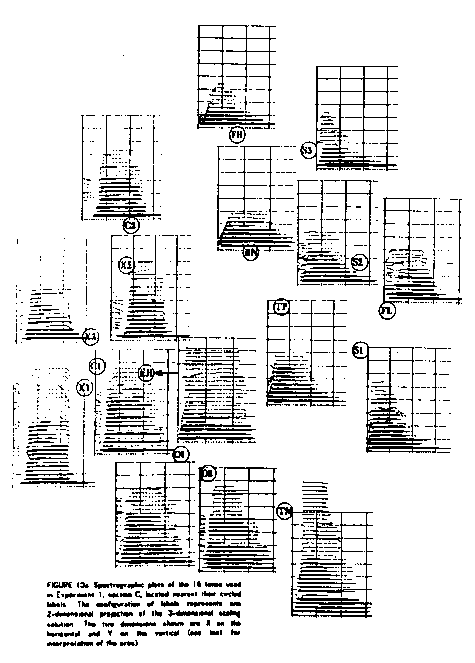
Figure 2: A 2-D similarity study of various timbres.
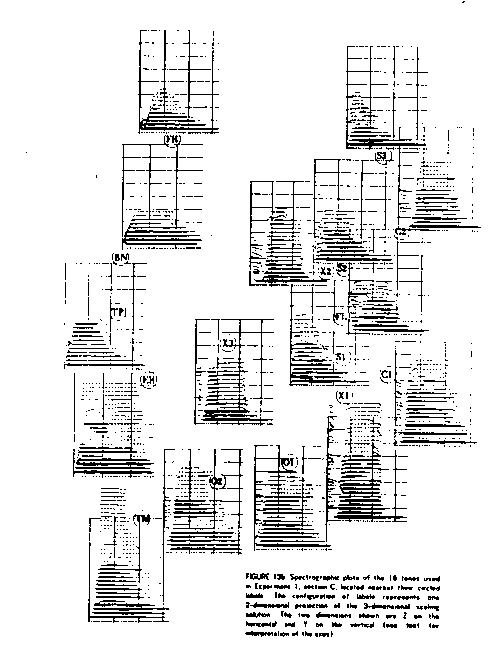
Figure 3: Same similarity study, plotted on different axes.

Figure 4: Same similarity study, plotted in 3-D space.
Listening
The study of psychoacoustics is devoted to the human side of the interface. Findings about what makes a percept, interesting in their own right, are also coupled to progress in synthesis and automatic recognition. In 1990, Al Bregman published Auditory Scene Analysis and galvanized a movement to understand how primitive perceptual operations build to competence in receiving acoustic communication and parsing the sounds of the world. He describes the problem with Figure 5.
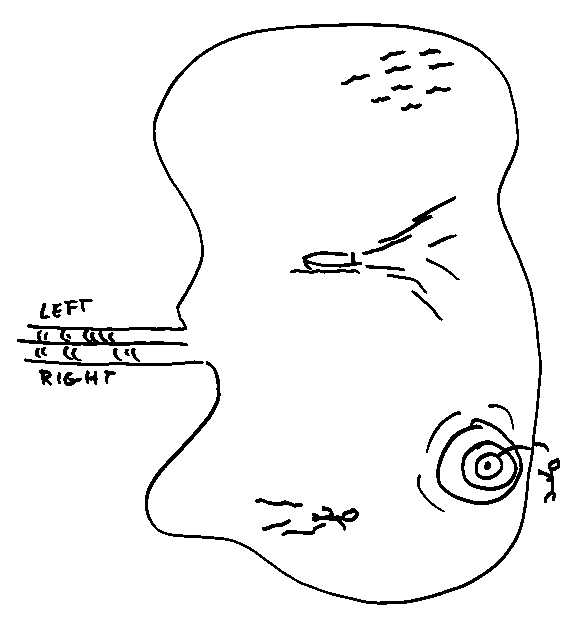
Figure 5: Auditory Scene Analysis, Lake Example.
A lake is inhabited by all manner of wave-making events. The waves combine as they reach two narrow channels. The auditory system's task is to create symbolic representations of the wave signals.
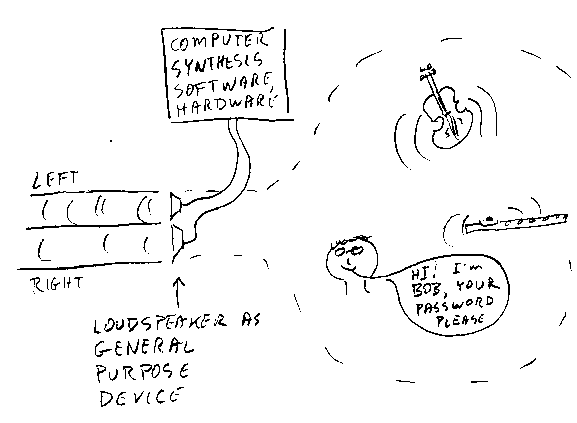
Figure 6: Virtual Scene Synthesis.
Figure 6 takes the idea into the realm of the HCI designer's intent. Sound generation devices should create "virtual" characters in the auditory scene.
Listen to the emergence of 3 voices as your ear copes to keep up with the alternation of wide pitch variation at high speed in
[streaming1.wav (1.5 MB)]
(mpg, 263kB)
. This function of the listener to split sounds into convenient sources can also depend on timbre differences
[streaming3.wav (1.4 MB)]
(mpg, 262B)
. This streaming illusion is an example of the effect the listener's auditory system can have in "receiving a message" from the HCI designer.
Representation of Events
Listening is one our means for knowing what's out in the world. Through our mechanical and acoustic equipment (voice, stretched strings, membranes, tubes, rattles, etc.) sounds emerged as a means to communicate thoughts from one to another. Alphabets and music notation evolved as a means to record and manipulate events. Very recently, digital forms of these codes have become convenient for such manipulation. ASCII and MIDI are abstractions that represent sound events but are very distant from the actual behavior of the sound producing sources themselves. Music made with MIDI is sometimes limited to the kinds of on / off control it is best known for. The limitation is not in the code, but in its application by the user.
It is often difficult to segment time-varying parts that go into making up the production of a sound event. For example the word "say" requires the following sequence of moves: close jaw, move up tongue tip to back of teeth while curling upper lip, start pumping air from lungs while constricting throat, after a good "sss" is delivered, drop tongue and jaw, fire up the voice box with throat articulators on "ay", close back of tongue to "ie" position, let off air pressure. Further complicating this description is that beginning and ending moves will vary according to preceding and following utterances; and pitch and loudness envelopes will depend on phrasing.
Figure 7 gives a picture of the relationship between strings in an energetic cello piece. To play this, the left and right hands are in a complex choreography of moves, sometimes coordinated, sometimes independent. As with speech, moves may be incomplete, but are inferred by the listener.
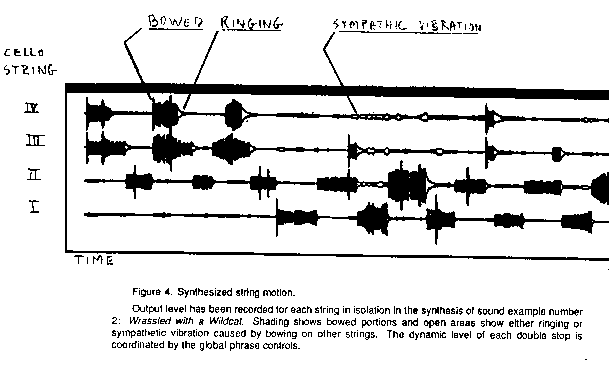
Figure 7: An example of complex Cello action.
More on Creating Acoustic Characters
Real communication events are messy. Figure 8 is a short transription of a dialogue between three speakers.

Figure 8: Transcription of a three-person dialog.
The flow of information is complex and moves in fits and starts. Something similar would be found in any recorded natural dialogue (try it, or put
[dialogue.wav (68 kB)]
(mpg, 135 kB!)
in an audio editor). After segmenting as best as possible, it becomes evident that the "non-linear" flow of conversation at this level of observation is in fact an intricate gating of information transfer. See W. Chafe, Discourse, Consciousness and Time (U. Chicago 1994) for a linguist's approach to this type of analysis.
The opening of a Beethoven Sonata, Figure 9, was played by two expert performers and analyzed for differences.

Figure 9: Beethoven sonata used to compare performers' interpretations.
Figure 10 graphs the note timings and velocities recorded by a Disklavier.

Figure 10: Comparison of the performers' renditions.
The study (Chafe and O'Modhrain, ICMC 1996, Hong Kong) found extreme differences of personality in the two renditions and a set of percepts that give rise to these differences.
To provide an example of capturing compositional character,
[pag-bachOrg.wav (6.4 MB)]
(mpg, 1.2MB)
is a hybrid of the character of two pieces to create a third. Pagannini's Caprice #24 was analyzed and combined with Bach's famous organ prelude to create something new and musically interesting. The analysis and hybridization were carried out entirely algorithmically (example by Jonathan Berger).
Sounds Sources are Messy, too.
Briefly, the traits of (non-linear feedback) chaotic systems are observed in many of the instruments we use to make sounds (for example, subharmonics in an oboe attack, figure 11).

Figure 11: Oboe Attack, Showing Transient Subharmonic.
This means that their control is state-sensitive, ie. that if you move a control slider to a certain point and expect a particular response you may or may not get it. Mechanical instruments provide cues to the player through the lips or hands about stability of oscillation and important inflections in the oscillator's behavior. For example, the bugle has a distinct feel when transitioning from one overtone to another. Figure 12 diagrams a system for transferring this quality to the finger controlling the lip tension of an electronic bugle.
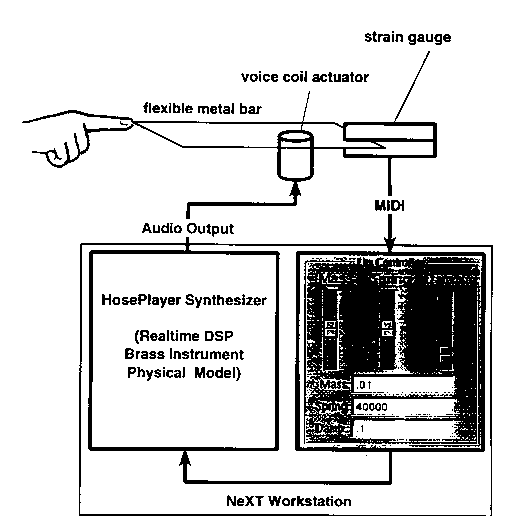
Figure 12: System for Haptic (Tactile) Feedback of Mode Transitions.
14-Nov-96, stilti